أفادت تقارير أن شركتي آبل ونVIDIA وAnthropic استخدموا نصوص يوتيوب لتدريب نماذج الذكاء الاصطناعي دون الحصول على إذن.
Most people like

اكتشف عالم الألعاب التفاعلية المدعومة بالذكاء الاصطناعي، التي تجذب وتسلّي الأطفال والبالغين على حد سواء. تمزج هذه الألعاب المبتكرة بين التقنية واللعب، مما يعزز الإبداع والتعلم من خلال الحوار التفاعلي. سواء كنت تبحث عن هدية أو وسيلة جديدة لتحفيز اللعب الإبداعي، فإن هذه الرفاق المدعومين بالذكاء الاصطناعي يقدمون مرحاً وفوائد تعليمية لا نهاية لها للجميع. استكشف كيف يمكن لهذه الألعاب تحسين مهارات التواصل وتعزيز التفاعل الاجتماعي بشكل فريد وممتع.
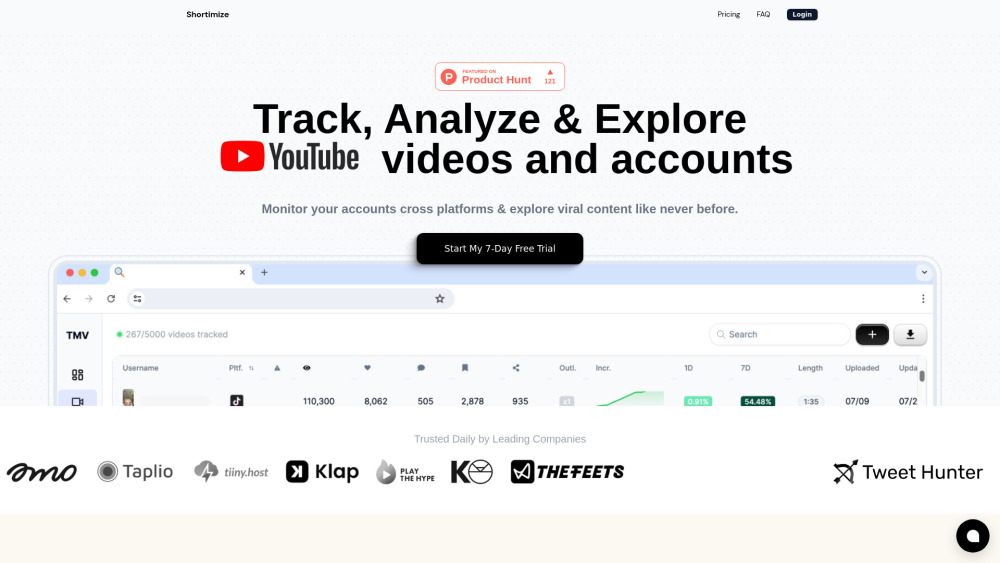
تقديم منصة شاملة مصممة لتتبع وتحليل مقاطع الفيديو القصيرة، مما يمكّن المبدعين والمسوقين من تحسين محتواهم بفاعلية.
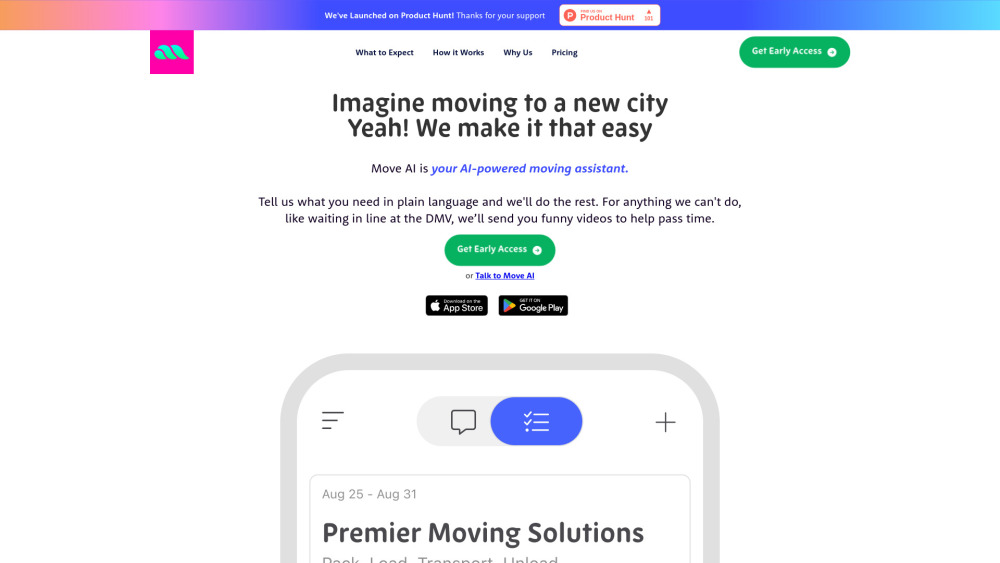
هل تشعر بالارتباك بسبب فكرة الانتقال القادم؟ تم تصميم مساعدنا الذكي المدعوم بالذكاء الاصطناعي لتبسيط عملية الانتقال، مما يجعلها أسهل وأكثر كفاءة. بدءًا من تنظيم مهام الانتقال وصولاً إلى العثور على أفضل الخدمات التي تناسب احتياجاتك، تقدم منصتنا الذكية دعمًا شخصيًا في كل خطوة. ودع الفوضى المرتبطة بالانتقال واستمتع بتجربة أكثر سلاسة ومتعة مع تقنيتنا المبتكرة. دعنا نساعدك في تحويل انتقالك إلى انتقال سلس.
Find AI tools in YBX
Related Articles
Refresh Articles