استقرار AI تطلق Stable Audio: ثورة في تصميم الصوت للمحترفين
Most people like
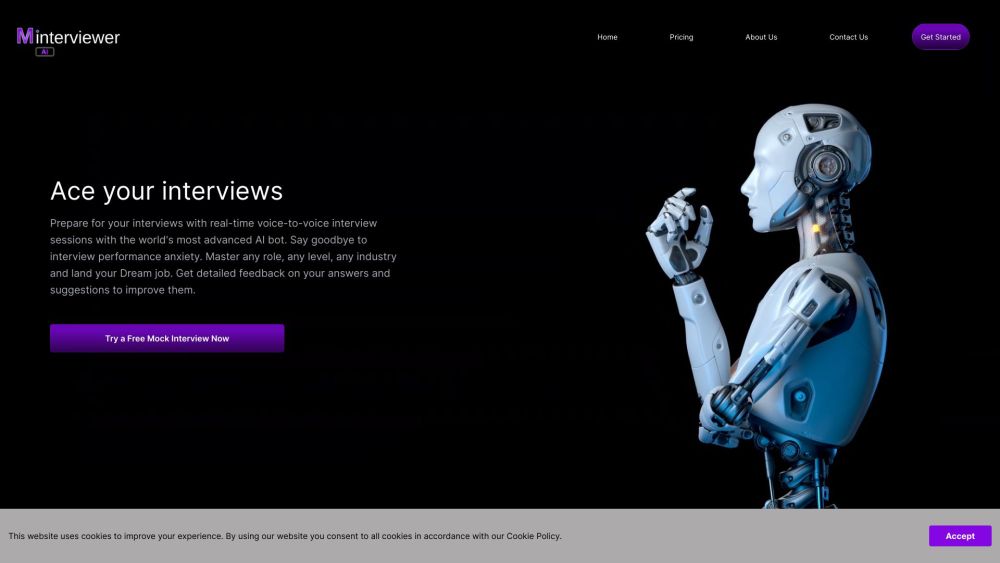
عزز مهاراتك من خلال مقابلات تجريبية فورية وتعليقات مدفوعة بالذكاء الاصطناعي
اختبر قوة الذكاء الاصطناعي كمدرب شخصي لك مع مقابلاتنا التجريبية الفورية والتعليقات الفورية. تقدم منصتنا سيناريوهات مقابلات واقعية، مما يساعدك على التحضير بفعالية مع الحصول على رؤى مصممة لتحسين أدائك. استعد لتحويل مهاراتك في المقابلات وزيادة ثقتك بنفسك!

تقديم مساعدك المدعوم بالذكاء الصناعي لإدارة المهام اليومية بسهولة
في عالم حيث يعتبر الوقت جوهريًا، يمكن أن تحدث المساعدات المدعومة بالذكاء الصناعي ثورة في طريقة إدارة مهامك اليومية. استمتع بالمزيج المثالي من الكفاءة والراحة، مما يتيح لك تنظيم الروتين، وزيادة الإنتاجية، والتركيز على ما يهم حقًا. ودّع الضغوط ومرحبًا بحياة يومية منظمة وخالية من التوتر!
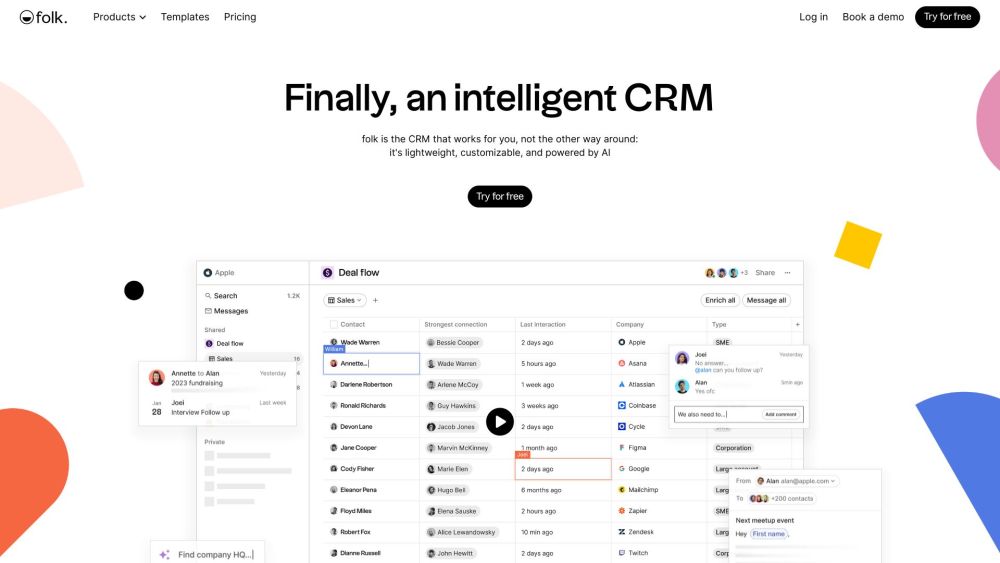
اكتشف حل CRM خفيف الوزن وقابل للتخصيص معزز بتقنية الذكاء الاصطناعي. مُصمم لتلبية احتياجات عملك الفريدة، تعمل هذه المنصة الذكية على تبسيط إدارة علاقات العملاء، مما يساعدك على زيادة الكفاءة وتحفيز النمو.

في عصر يلتقي فيه التكنولوجيا بالإبداع، تقوم الذكاء الاصطناعي (AI) بثورة في طريقة إنشاء الصور وتعديلها. من تحسين الصور الفوتوغرافية إلى إنتاج أعمال فنية رائعة، تمكّن أدوات الذكاء الاصطناعي الفنانين والمصممين من دفع حدود خيالهم. بينما نتعمق في القوة التحويلية للذكاء الاصطناعي في مجال الصور، سنستكشف تقنيات جديدة وتطبيقات تشكل مستقبل إنشاء المحتوى البصري. انضموا إلينا في هذه الرحلة لاكتشاف كيف أن الذكاء الاصطناعي ليس مجرد أداة، بل هو محفز للتعبير الإبداعي.
Find AI tools in YBX
Related Articles
Refresh Articles