تساعد DataStax المؤسسات على تجاوز معاناة RAG من خلال تحديث أدوات الذكاء الاصطناعي المحسّنة.
Most people like
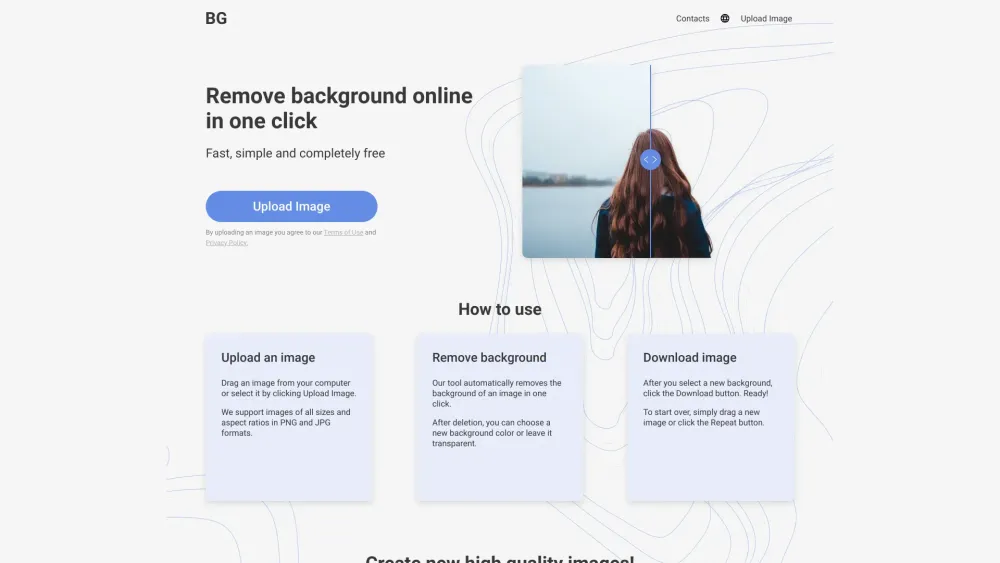
قم بإزالة الخلفية من صورك بسهولة بنقرة واحدة فقط! سواء كنت ترغب في تحسين الصور لمشاريع شخصية أو عروض احترافية، فإن أداتنا السهلة الاستخدام تبسط عملية التحرير، مما يمكنك من تحقيق نتائج مذهلة في وقت قصير. ودّع البرامج المعقدة واستقبل التحرير السهل للصور!
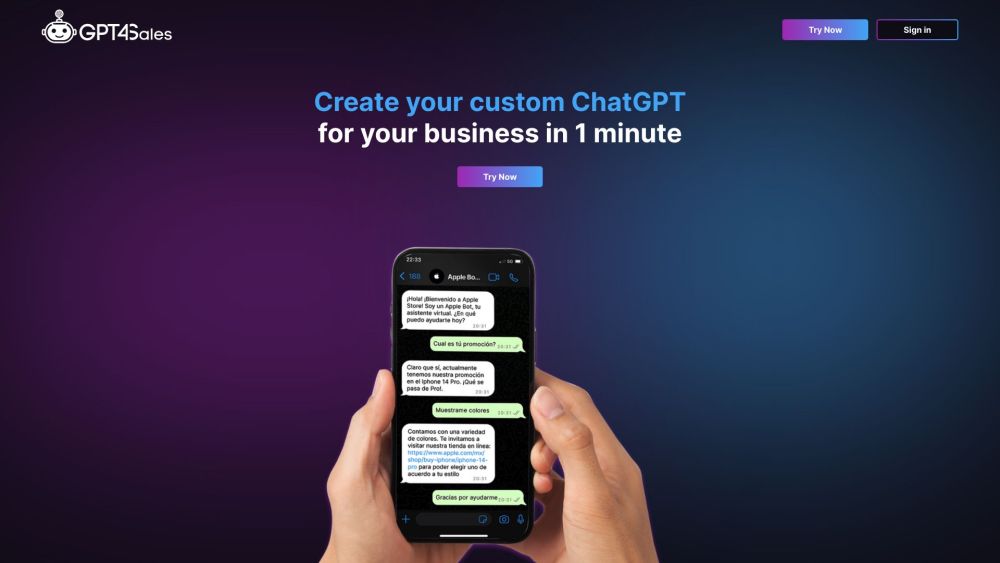
اكتشف كيف يمكنك تعزيز تجربة المراسلة الخاصة بك مع حل GPT مُخصص لتطبيقات واتساب وتيليجرام! تتيح لك هذه التقنية المبتكرة إنشاء شات بوت شخصي يمكنه التفاعل مع المستخدمين، والإجابة على الأسئلة، وتبسيط المحادثات، مما يجعل تواصلك أكثر كفاءة وفعالية. سواء كنت مؤسسة تسعى لتحسين التفاعل مع العملاء أو فردًا يرغب في تجربة محادثة أكثر ديناميكية، فإن استغلال GPT مخصص يمكن أن يغير طريقة تواصلك. استكشف الإمكانيات وارتقِ بتجربة المراسلة لديك اليوم!
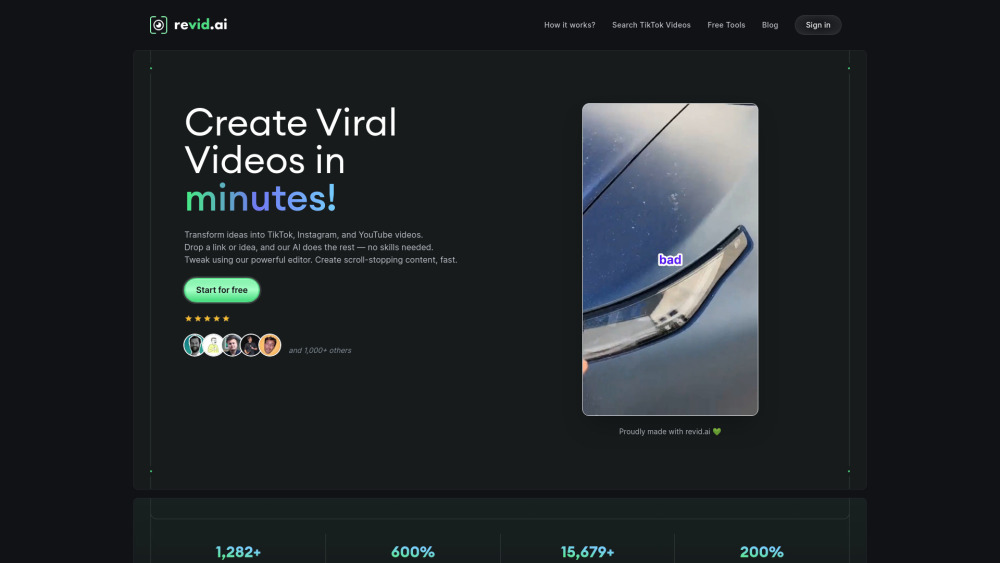
افتح طاقة أداة مدعومة بالذكاء الاصطناعي مصممة لإنشاء مقاطع فيديو قصيرة فيروسية جذابة بسهولة. تستفيد هذه الحلول المبتكرة من الذكاء الاصطناعي المتقدم لتبسيط عملية إنتاج الفيديو، مما يضمن أن محتواك لا يجذب الانتباه فحسب، بل يتفاعل أيضًا مع المشاهدين. سواء كنت منشئ محتوى أو مسوقًا أو صاحب عمل، فإن هذه الأداة تجعل من الصعب تصميم مقاطع فيديو قابلة للمشاركة وجذابة أكثر من أي وقت مضى. احتضن مستقبل تسويق الفيديو وشاهد جمهورك ينمو!
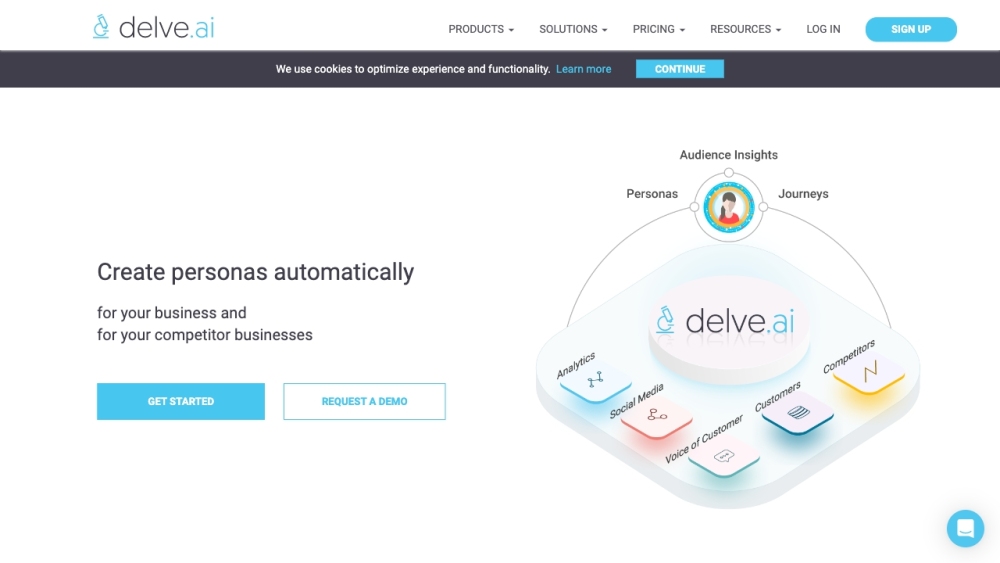
اكتشف كيف تخلق Delve AI شخصيات المشتري التفصيلية من خلال تحليل البيانات، مما يوفر رؤى قيمة حول تفضيلات وسلوكيات العملاء.
Find AI tools in YBX
Related Articles
Refresh Articles