تعلن OpenAI عن إطلاق أداة إدارة الوسائط في عام 2025، مما يمكّن المبدعين من حظر تدريب الذكاء الاصطناعي.
Most people like
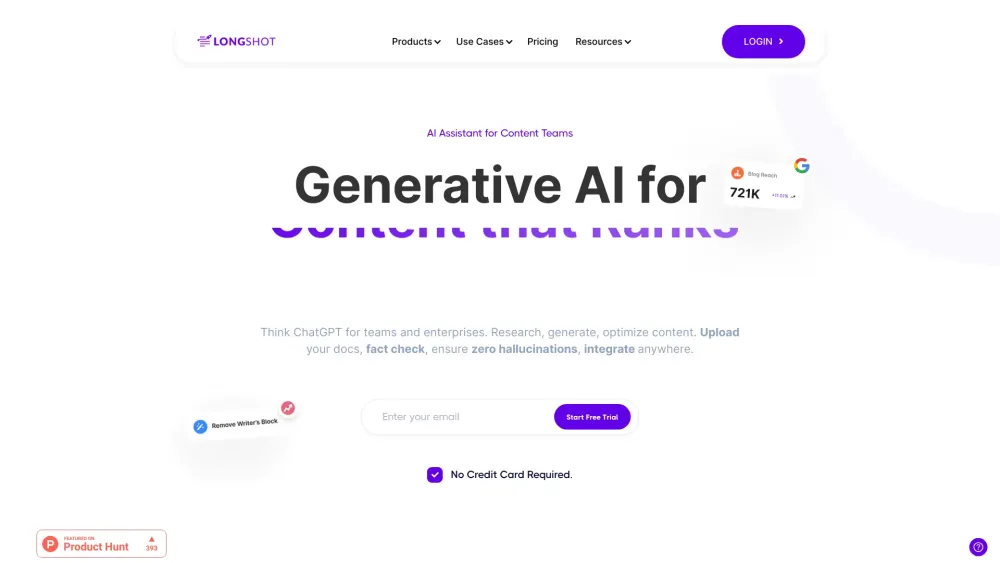
نقدم لكم منصة ذكاء اصطناعي مصممة لتلبية جميع احتياجاتكم في إنشاء المحتوى! سواء كنتم مسوقين أو مدونين أو أصحاب أعمال، فإن هذه الحلول المبتكرة تسهل عملية توليد المحتوى، مما يضمن الجودة والكفاءة. اكتشفوا كيف يمكن لأدواتنا المدفوعة بالذكاء الاصطناعي تعزيز إبداعكم وإنتاجيتكم، مما يجعل من السهل أكثر من أي وقت مضى إنتاج محتوى جذاب ومؤثر يتناسب مع جمهوركم. احتضنوا مستقبل إنشاء المحتوى اليوم!
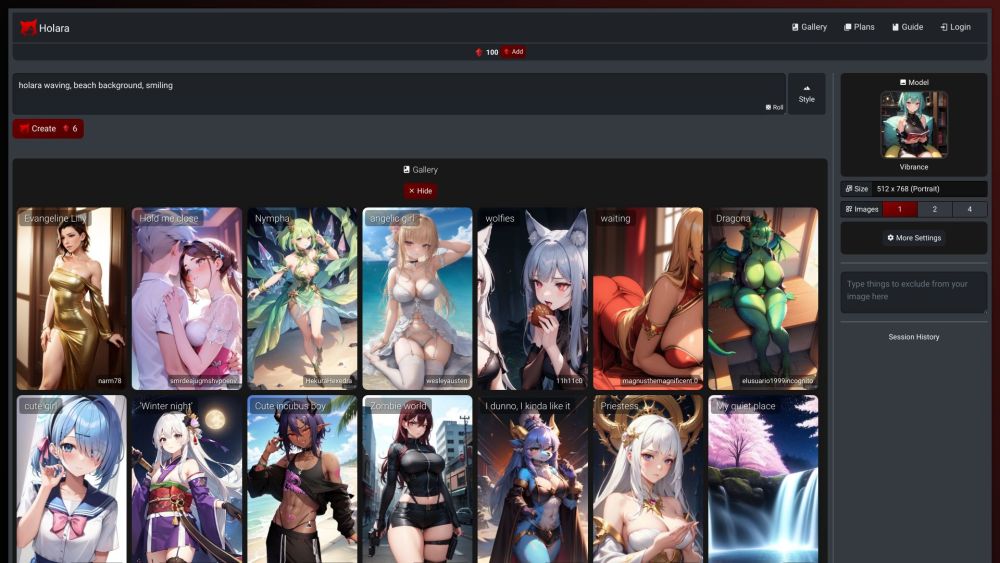
هل أنت من عشاق الأنيمي أو فنان طموح يسعى لتحقيق رؤى إبداعية؟ تقدم منصتنا المتطورة المدعومة بالذكاء الاصطناعي طريقة مبتكرة لإنشاء أعمال فنية مذهلة للأنيمي بكل سهولة. بفضل واجهتنا سهلة الاستخدام والخوارزميات المتقدمة، يمكنك تحويل أفكارك إلى مرئيات رائعة في غضون لحظات. انضم إلى مجتمع من المبدعين وأطلق خيالَك باستخدام أدواتنا القوية المصممة خصيصًا لفن الأنيمي. احتضن مستقبل الإبداع مع منصتنا المدفوعة بالذكاء الاصطناعي اليوم!
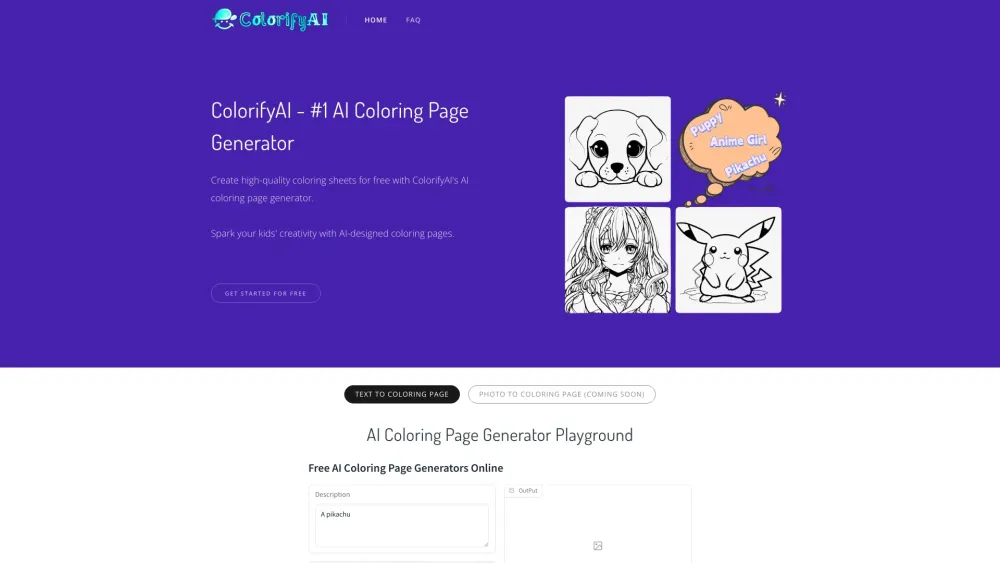
هل تبحث عن طريقة ممتعة ومبتكرة للتفاعل مع الفن؟ يمكن لمولد صفحات تلوين بتقنية الذكاء الاصطناعي تحسين تجربتك الإبداعية من خلال تحويل الصور والأفكار إلى صفحات تلوين فريدة. سواء كنت والدًا تبحث عن أنشطة مسلية لأطفالك، أو فنانًا يبحث عن إلهام، أو شخصًا يسعى للاسترخاء مع هواية مريحة، فإن هذه الأداة المتطورة تقدم إمكانيات لا نهائية. اكتشف كيف يمكن للذكاء الاصطناعي أن يُشعل خيالك ويجلب صفحات التلوين الخاصة بك إلى الحياة!
تعتبر TeleportHQ منصة مبتكرة ذات شيفرة منخفضة مصممة لتبسيط تصميم وتطوير الواجهات الأمامية، مما يسهل على المطورين والمصممين إنشاء واجهات مذهلة دون الحاجة إلى خبرة برمجية واسعة.
Find AI tools in YBX
Related Articles
Refresh Articles