جوجل تكشف أسرار GPT-3.5 من OpenAI: اتهامات بتسرب معلومات أساسية!
Most people like
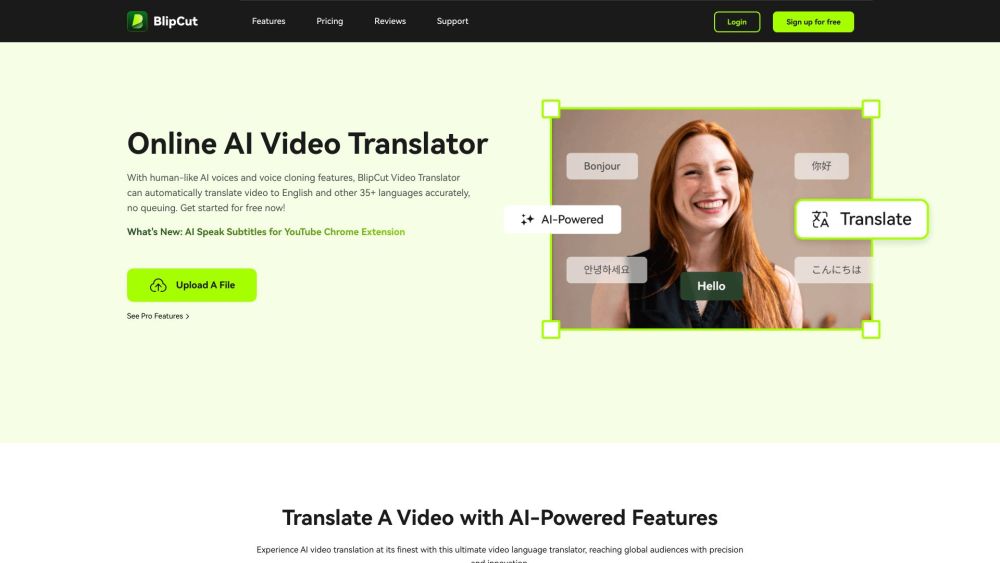
حوّل مقاطع الفيديو الخاصة بك باستخدام ترجمة مدعومة بالذكاء الاصطناعي تقدم تعليقات صوتية تشبه صوت الإنسان. عزز إمكانية الوصول ووسّع جمهورك العالمي بسهولة.
نقدم لكم مزودًا رائدًا لحلول تحليل الفيديو المدعومة بالذكاء الاصطناعي، مكرسًا لتحويل البيانات المرئية إلى رؤى قابلة للتنفيذ. تستخدم تقنيتنا المبتكرة خوارزميات متقدمة لتعزيز الأمن، وتحسين العمليات، ودفع اتخاذ القرارات المستنيرة. انضموا إلينا في إعادة تعريف كيفية استفادة الشركات من بيانات الفيديو لتحسين الكفاءة والسلامة في بيئة اليوم السريعة.

في عالم الرقمية السريع اليوم، تعد الاتصالات الفعالة ضرورية. أداة الدردشة غير المقيدة تمكّن المستخدمين من تجربة تفاعلات فورية دون أي حدود. سواء كنت تتعاون مع فريق، أو تتفاعل مع عملاء، أو ببساطة تتواصل مع أصدقاء، فإن هذه الأداة تعزز كفاءة التواصل وتقوي العلاقات. استكشف كيف يمكن لأداة الدردشة غير المقيدة أن تحول محادثاتك وتقرب الناس من بعضهم البعض، متجاوزة الحواجز للحوار الفعّال.

في ظل المشهد التنافسي اليوم، يلعب استرجاع وتحليل براءات الاختراع العالمية بفعالية دوراً حاسماً في دفع الابتكار وحماية الملكية الفكرية. من خلال جمع وفحص بيانات براءات الاختراع من جميع أنحاء العالم بشكل منهجي، يمكن للشركات والباحثين تحديد الاتجاهات، واكتشاف المعلومات التنافسية، واتخاذ قرارات مستنيرة. لا تعزز هذه العملية التخطيط الاستراتيجي فحسب، بل تعزز أيضاً النمو من خلال مواكبة التطورات التكنولوجية وتحولات السوق. انضم إلينا لاستكشاف الأساليب والأدوات الأساسية لتجاوز تعقيدات معلومات براءات الاختراع العالمية لتعزيز استراتيجية الابتكار الخاصة بك.
Find AI tools in YBX
Related Articles
Refresh Articles