يُزعم أن فريق الذكاء الاصطناعي في NVIDIA قام بجمع مقاطع فيديو من يوتيوب ونيتفليكس دون الحصول على إذن.
Most people like
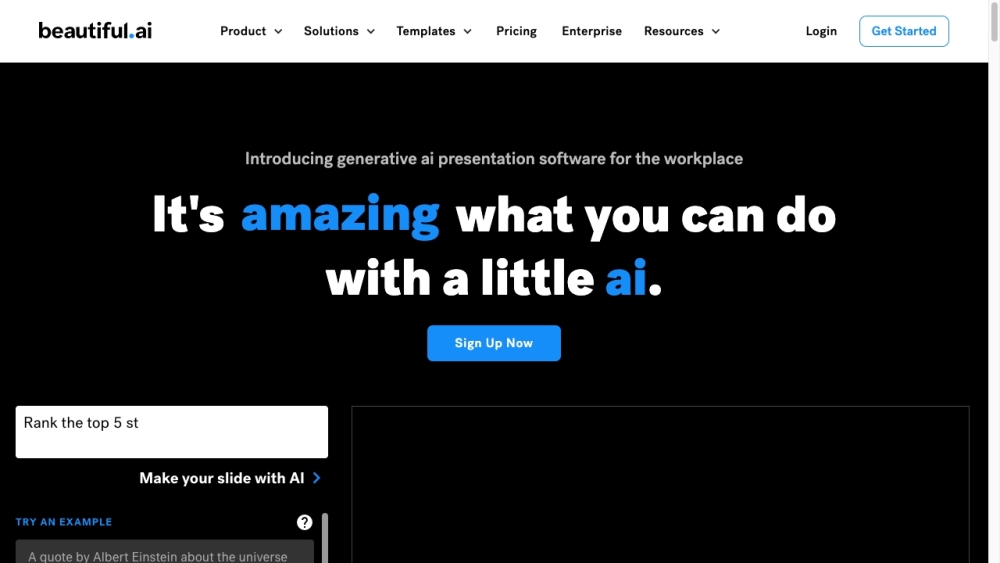
Beautiful.ai هو أداة مبتكرة تهدف إلى تمكين الفرق من إنشاء عروض تقديمية جذابة بصريًا بسهولة. بفضل ميزاته سهلة الاستخدام، يبسط عملية التصميم، مما يجعلها متاحة لأي مستخدم.
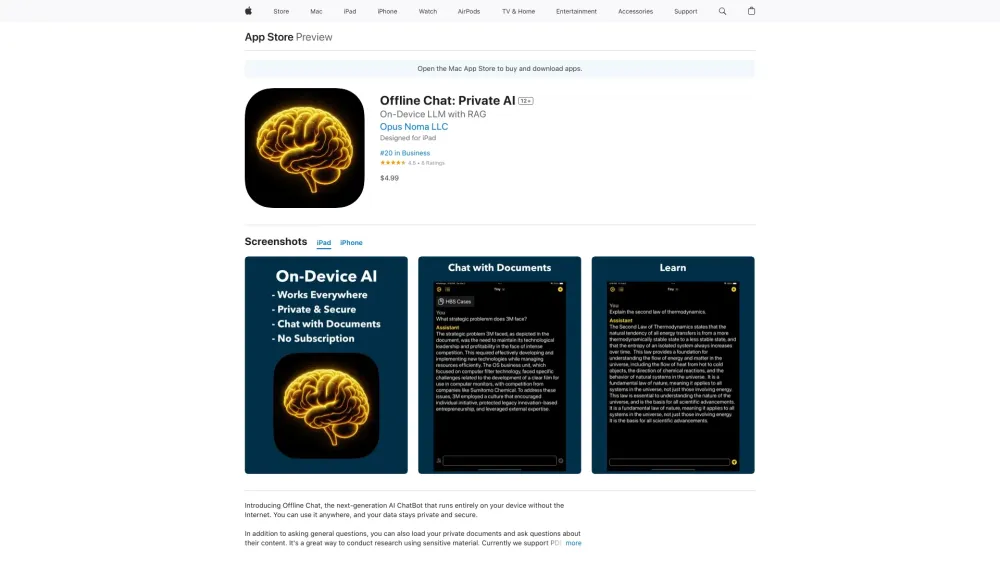
في المشهد الرقمي اليوم، يمثل دمج نماذج اللغة الكبيرة على الجهاز (LLMs) مع تكنولوجيا تعزيز الاسترجاع (RAG) إنجازًا كبيرًا في مجال الذكاء الاصطناعي. لا تعزز هذه المقاربة الابتكارية قدرات أنظمة الذكاء الاصطناعي فحسب، بل تضمن أيضًا تشغيلها بكفاءة عند الحافة، مما يقلل من زمن الاستجابة ويزيد من الأداء. بينما نستكشف تداخل معالجة البيانات على الجهاز وRAG، ستكتشف كيف تحول هذه التآزر تجارب المستخدمين وتدفع الحلول الذكية عبر تطبيقات متعددة. انضم إلينا في الغوص أعمق في هذه التكنولوجيا الثورية!
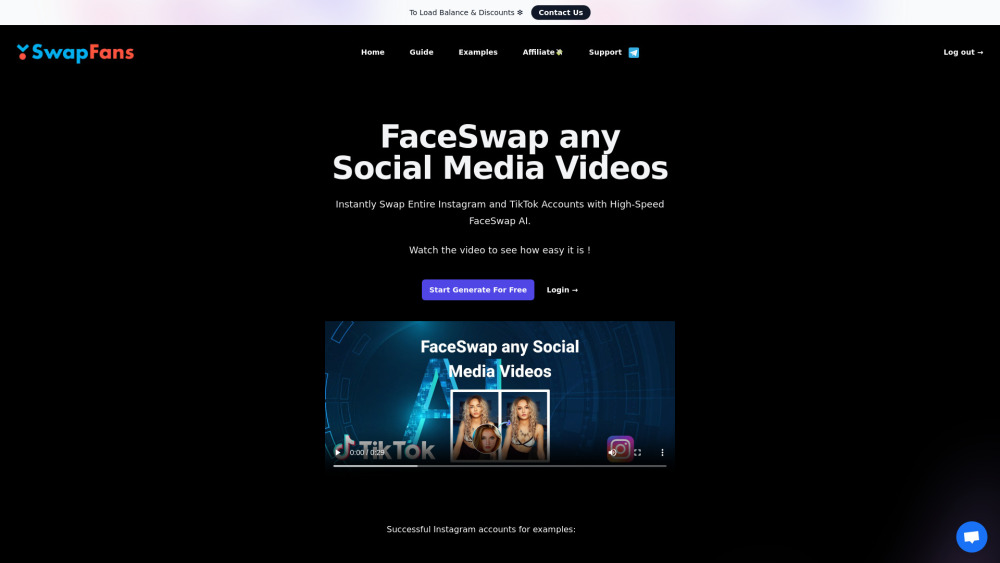
حوّل مقاطع الفيديو الخاصة بك على وسائل التواصل الاجتماعي باستخدام تقنية كشف الوجه المدعومة بالذكاء الاصطناعي
استفِد من قوة الذكاء الاصطناعي من خلال تبديل الوجوه بسلاسة في مقاطع الفيديو الخاصة بك على وسائل التواصل الاجتماعي. عزز محتواك واجذب جمهورك كما لم يحدث من قبل مع أداتنا المبتكرة لتبديل الوجوه. اكتشف مدى سهولة إنشاء مقاطع فيديو ممتعة وقابلة للمشاركة تأسر الانتباه وتعزز التفاعل عبر المنصات.
Find AI tools in YBX
Related Articles
Refresh Articles