Alibaba presenta Qwen2-VL: el nuevo modelo de IA capaz de analizar videos de más de 20 minutos.
Most people like

En una era donde el contenido de videojuegos es el rey, los streamers están en constante búsqueda de formas de mejorar sus transmisiones y conectar con su audiencia. Un editor de video impulsado por IA, diseñado específicamente para streamers de videojuegos, ofrece herramientas innovadoras que optimizan el proceso de edición, mejoran la calidad del contenido y elevan la participación de los espectadores. Con características avanzadas adaptadas al mundo gamer, esta tecnología no solo ahorra tiempo, sino que también potencia la creatividad, permitiendo a los streamers concentrarse en lo que más les apasiona: jugar. ¡Descubre cómo la edición de video impulsada por IA puede transformar tu experiencia de streaming!
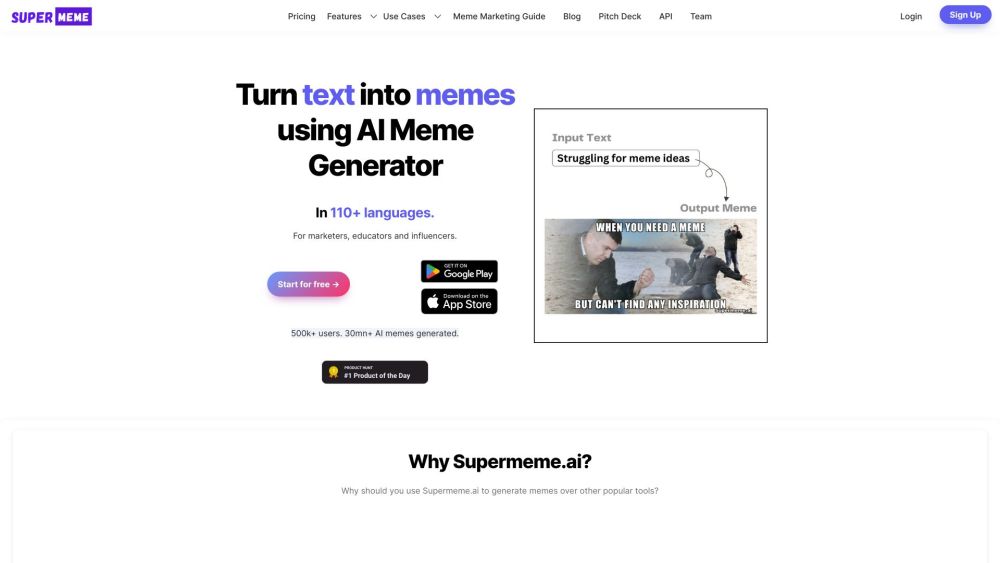
Transforma texto en memes atractivos sin esfuerzo con IA: ¡no se necesitan habilidades de edición de imágenes!
Explora soluciones de seguridad en IA de vanguardia diseñadas para mejorar la confiabilidad y seguridad de los sistemas de inteligencia artificial. Al priorizar el desarrollo seguro de la IA, las organizaciones pueden mitigar eficazmente los riesgos mientras aprovechan el potencial de la inteligencia artificial.
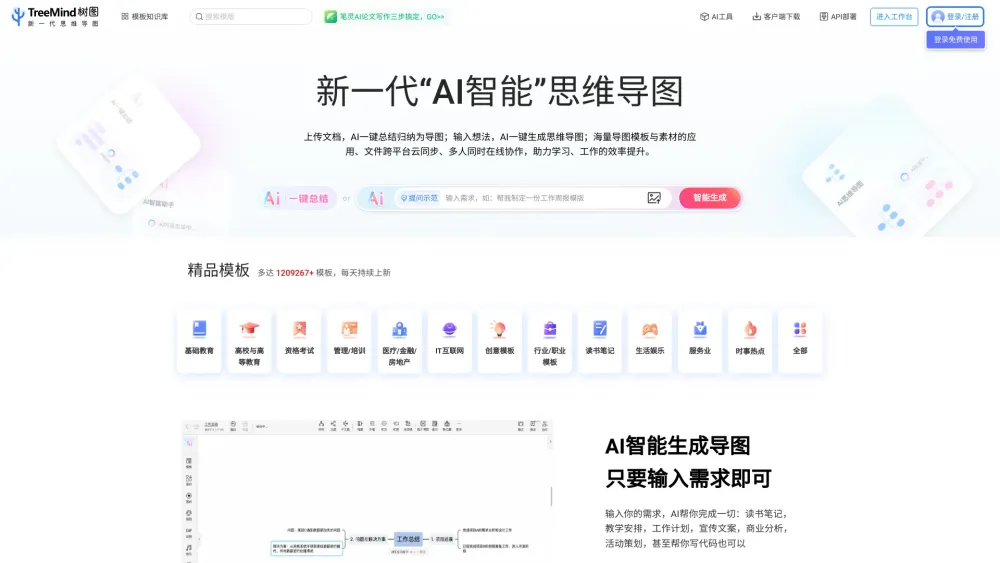
Descubre el poder del software de mapas mentales basado en IA, diseñado para ayudarte a visualizar tus pensamientos e ideas de manera efectiva. Esta herramienta innovadora potencia la creatividad, aumenta la productividad y agiliza tu proceso de lluvia de ideas, facilitando la organización y desarrollo de tus conceptos. Explora el impacto transformador de la IA en los mapas mentales y desbloquea tu potencial hoy mismo.
Find AI tools in YBX
