Amazon Investiga a Perplexity AI por Alegaciones de Rastreo No Autorizado de Sitios Web
Most people like
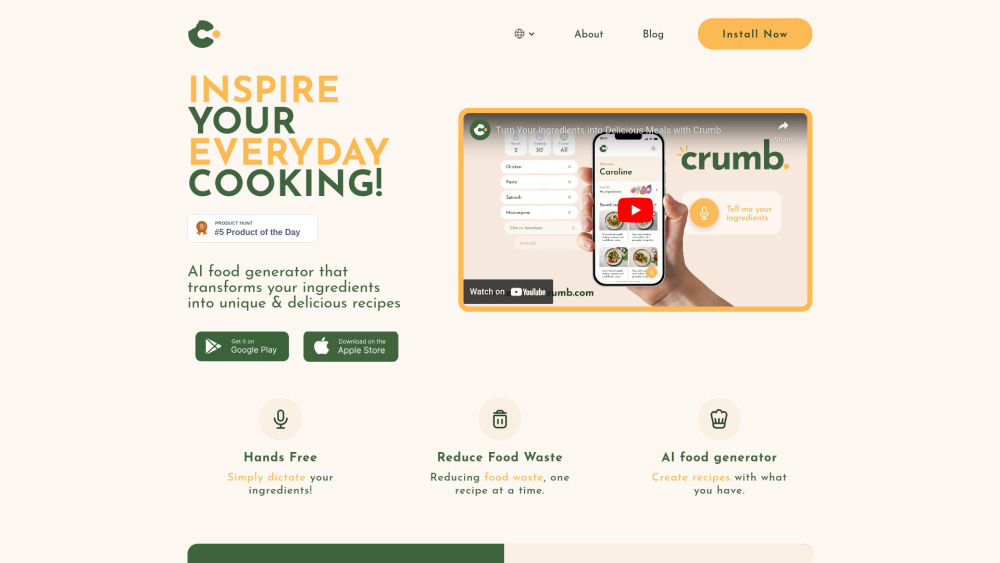
Descubre nuestro generador de recetas con inteligencia artificial que crea platos únicos adaptados a los ingredientes que tienes a mano. Desata tu creatividad culinaria y transforma tu despensa en una cocina gourmet con recetas personalizadas al alcance de tu mano.
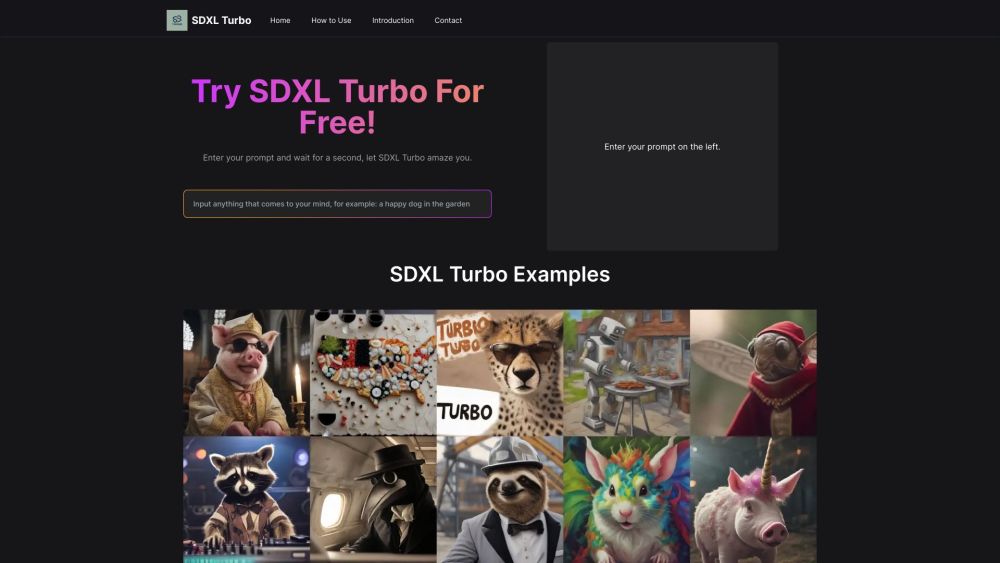
Experimenta una generación de imágenes de IA ultra-rápida y de alta calidad, impulsada por avanzada tecnología ADD.
En el mundo acelerado y tecnológico de hoy, las empresas de todo el mundo están recurriendo a la inteligencia artificial (IA) para mejorar la eficiencia y fomentar la innovación. Desde la automatización de tareas rutinarias hasta la provisión de información basada en datos, las soluciones de IA permiten a las organizaciones mantenerse competitivas y adaptarse a mercados en rápida transformación. Esta guía explora diversas tecnologías de IA adaptadas para empresas globales, mostrando cómo pueden transformar las operaciones, optimizar procesos y, en última instancia, contribuir al crecimiento sostenible. Descubre cómo implementar la IA puede revolucionar tu estrategia empresarial y posicionarte a la vanguardia de tu industria.

Desbloquea el poder de una herramienta de inteligencia artificial gratuita diseñada específicamente para mejorar imágenes. Ya seas fotógrafo, diseñador o simplemente alguien que busca realzar sus visuales, esta innovadora tecnología facilita la elevación de la calidad de tus imágenes sin comprometer los detalles. ¡Experimenta hoy las capacidades transformadoras del escalado de imágenes impulsado por IA!
Find AI tools in YBX
Related Articles
Refresh Articles