Kneron Mejora la Inteligencia Artificial en el Borde con Nuevas Funciones de Unidad de Procesamiento Neural y Servidor Edge GPT Actualizado
Most people like
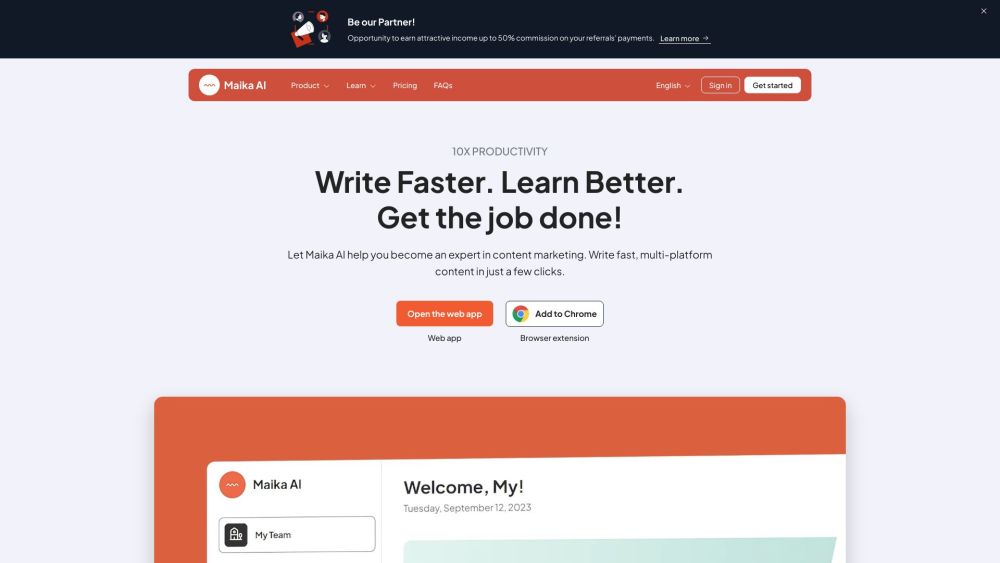
Descubre la herramienta definitiva de creación de contenido impulsada por IA, diseñada específicamente para marketers y creadores de contenido. Mejora tu estrategia de contenido, optimiza tu flujo de trabajo y conecta de manera efectiva con tu audiencia utilizando tecnología de inteligencia artificial de vanguardia. ¡Desbloquea tu potencial creativo y eleva tus campañas de marketing hoy mismo!
Socratic es una plataforma de aprendizaje innovadora diseñada para mejorar el aprendizaje de los estudiantes al ofrecer respuestas completas, explicaciones detalladas y contenido en video cautivador.
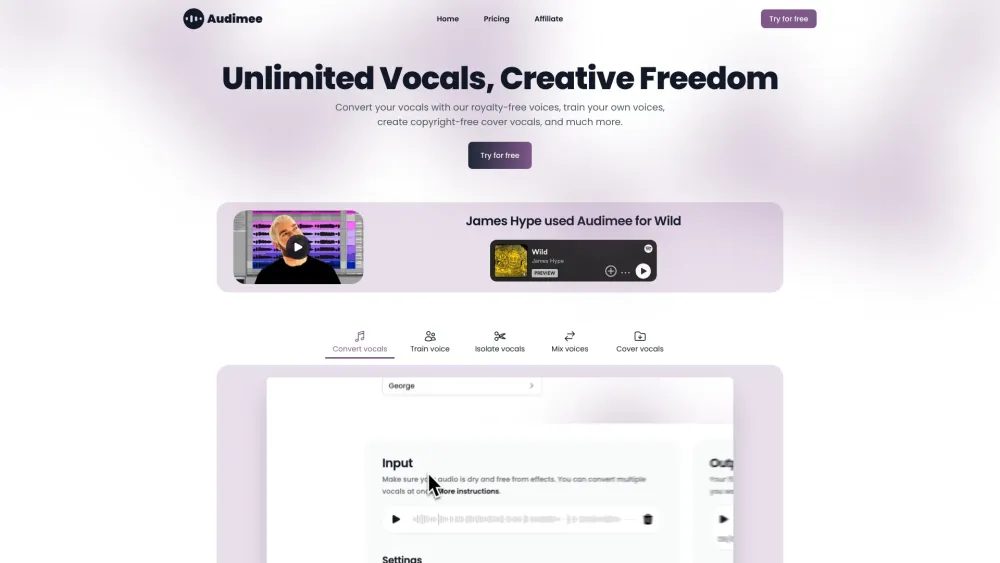
Desbloquea el poder de tu voz con nuestra avanzada herramienta de voz a voz, diseñada para elevar tus actuaciones vocales. Ya seas músico, podcaster o creador de contenido, esta tecnología transformadora te permite modificar y mejorar tus voces sin esfuerzo. Di adiós a las limitaciones y hola a las infinitas posibilidades para tu sonido. ¡Descubre cómo nuestra herramienta puede ayudarte a lograr resultados de calidad profesional que cautiven a tu audiencia!
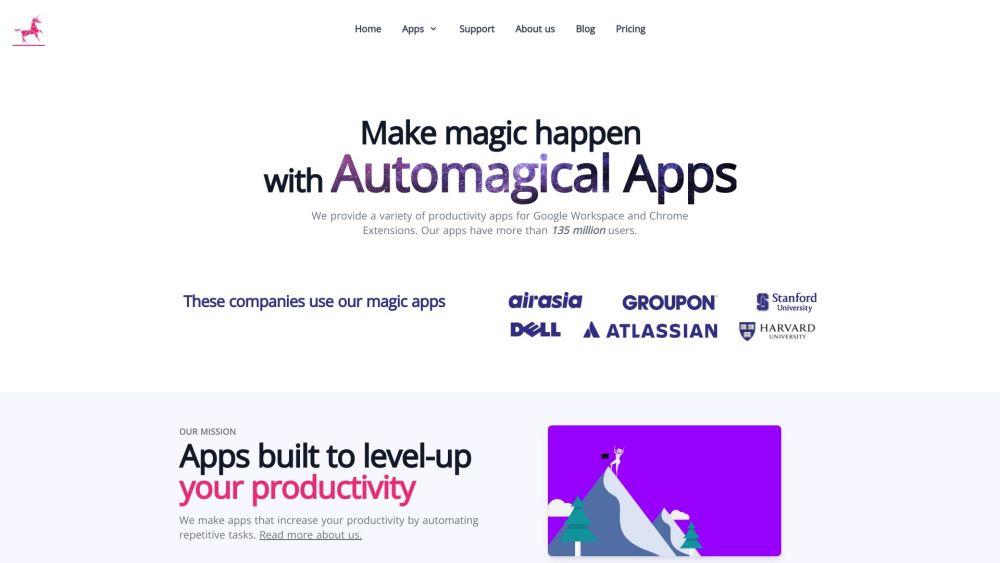
Descubre las mejores aplicaciones de productividad para Google Workspace y las extensiones esenciales de Chrome, confiadas por más de 3 millones de usuarios para mejorar la eficiencia y optimizar los flujos de trabajo.
Find AI tools in YBX
Related Articles
Refresh Articles