Los Gigantes de Silicon Valley Invierten Miles de Millones para Competir por Recursos de Datos de Entrenamiento de IA
Most people like

Presentamos una plataforma de rol con inteligencia artificial que te sumerge en cautivadoras historias interactivas. Sumérgete en un mundo donde puedes dar forma a tu narrativa, interactuar con personajes dinámicos y explorar aventuras ilimitadas. Ya seas un jugador experimentado o nuevo en el mundo del rol, nuestra plataforma ofrece una experiencia atractiva que potencia tu creatividad. ¡Únete a nosotros para desbloquear historias emocionantes y embarcarte en viajes inolvidables hoy mismo!

Descubre la plataforma integral de gestión financiera diseñada para potenciar tu crecimiento y éxito económico.
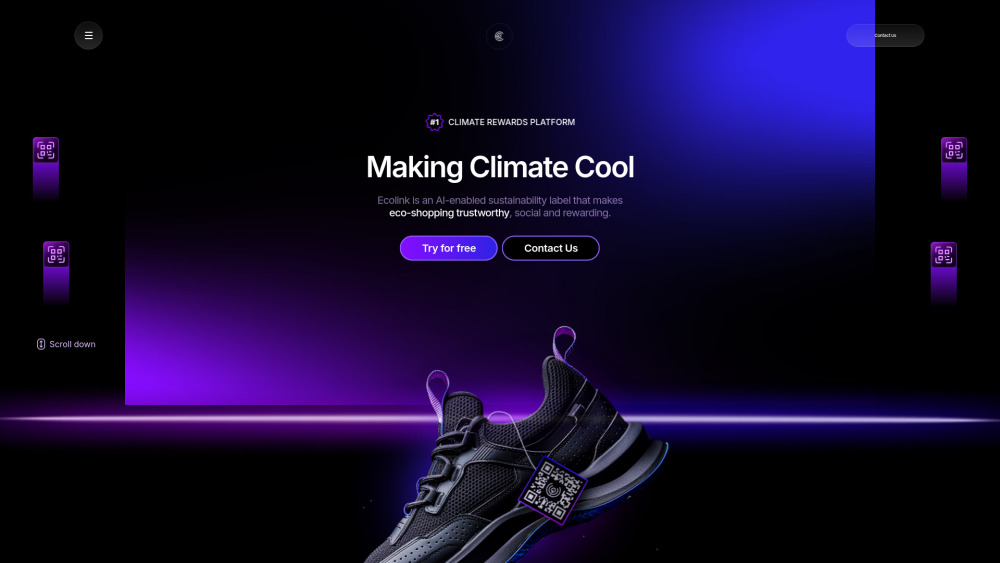
Presentamos una innovadora plataforma de sostenibilidad que combina inteligencia artificial y tecnología blockchain, diseñada para revolucionar nuestra manera de abordar la conservación ambiental. Aprovechando el poder de la inteligencia artificial y la tecnología blockchain, esta plataforma busca mejorar la transparencia, aumentar la eficiencia y promover prácticas sostenibles en diversas industrias. Únete a nosotros para transformar el futuro de la sostenibilidad a través de tecnología de vanguardia.
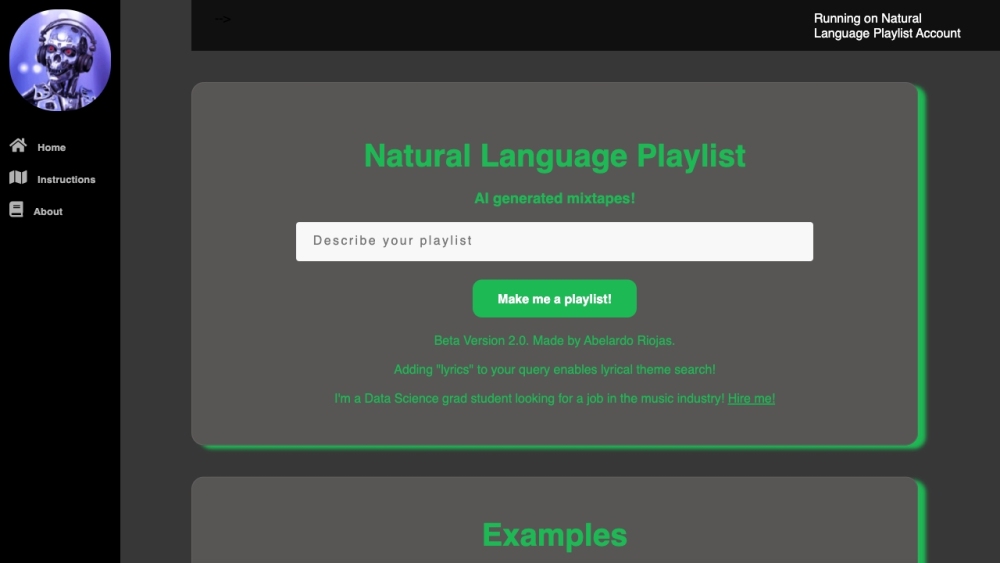
Descubre una innovadora plataforma de IA que crea mixtapes personalizados basados en tus descripciones únicas en lenguaje natural. Esta avanzada tecnología transforma tus palabras en una experiencia musical a medida, diseñada exclusivamente para ti.
Find AI tools in YBX
Related Articles
Refresh Articles