Modelos de IA Especializados: Rastreando la Ruta Evolutiva del Desarrollo de Hardware
Most people like
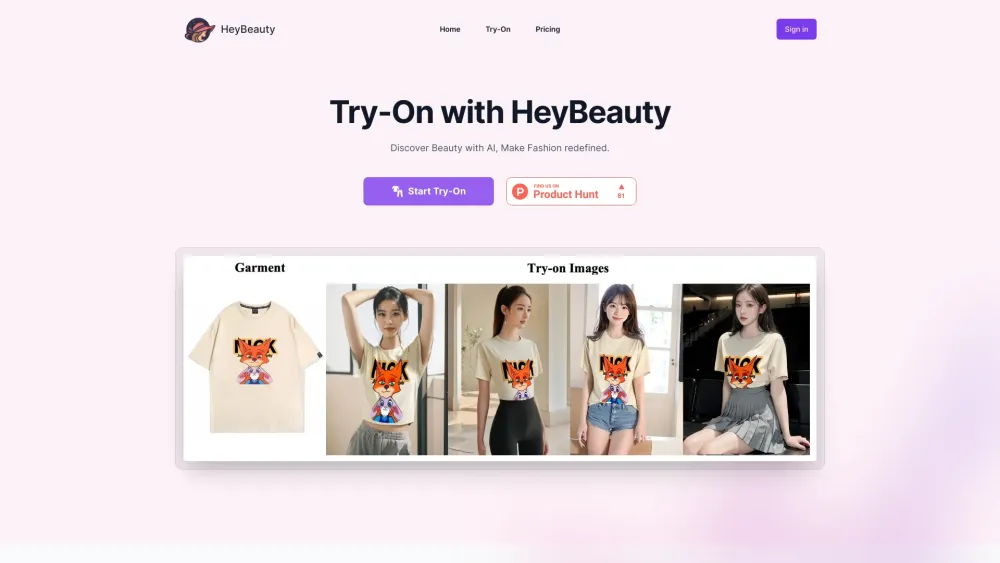
Transforma Tu Experiencia de Moda: Liberando el Futuro del Estilo
En el mundo acelerado de hoy, la manera en que interactuamos con la moda está evolucionando rápidamente. Descubre cómo las tecnologías innovadoras y los enfoques creativos están revolucionando el panorama de la moda, haciéndolo más personalizado, accesible y sostenible. Adéntrate en el futuro del estilo y aprende a mejorar tu viaje de moda como nunca antes.
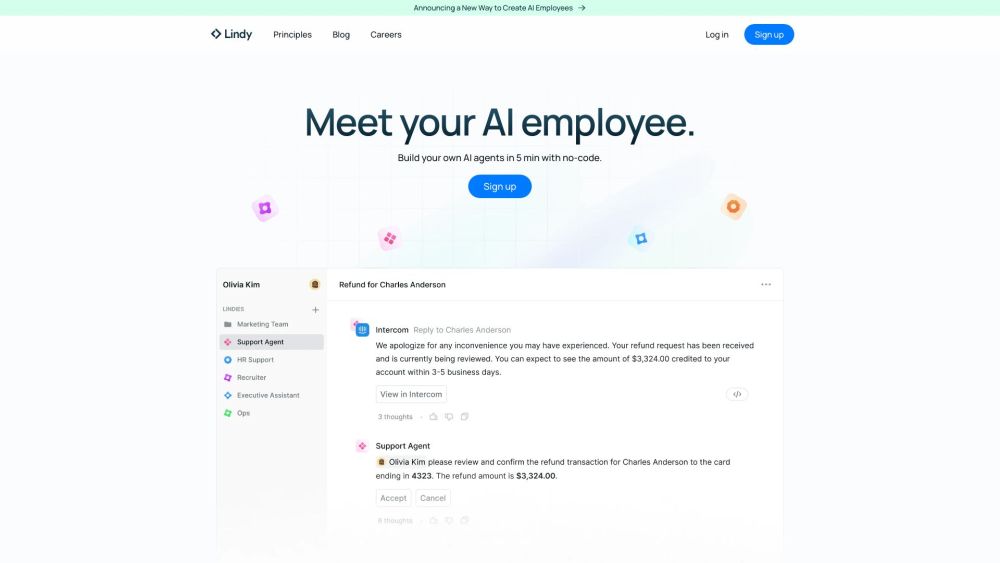
Crea tus propios agentes de IA sin esfuerzo—¡sin necesidad de programar!
Desbloquea el poder de la inteligencia artificial creando agentes personalizados sin conocimientos de codificación. Ya seas un propietario de negocio, un desarrollador o simplemente alguien curioso sobre la IA, nuestra plataforma te permite diseñar y desplegar agentes inteligentes adaptados a tus necesidades específicas. ¡Sumérgete en el mundo de las soluciones sin código y da vida a tus ideas de IA con facilidad!
Easy-Peasy.AI es una herramienta innovadora de inteligencia artificial diseñada para ayudar a los usuarios a crear contenido original rápidamente y mejorar sus habilidades de escritura de manera efectiva. Con sus características fáciles de usar, este poderoso recurso hace que la creación de contenido sea sencilla para todos.
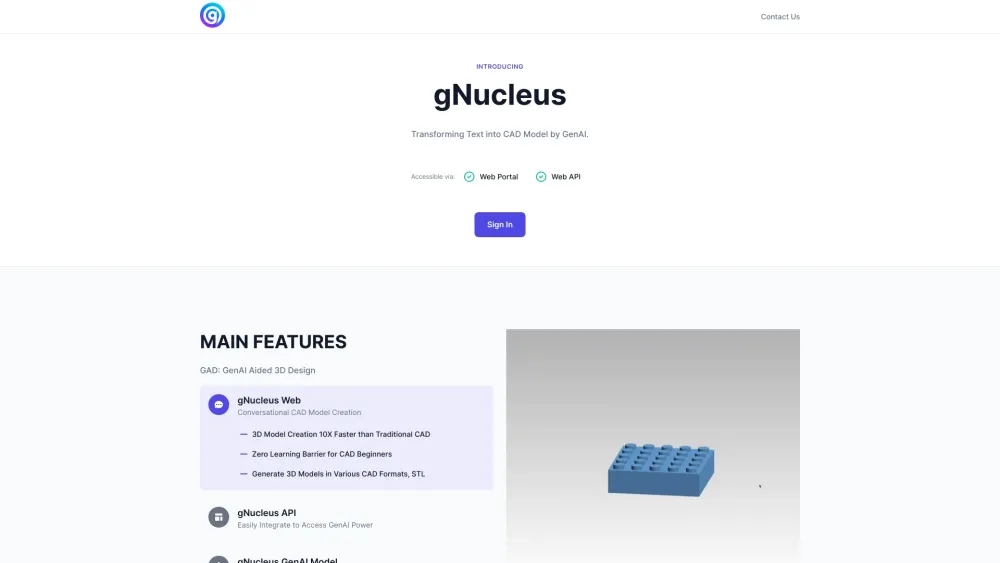
Transforma tus descripciones de texto en impresionantes modelos 3D CAD sin esfuerzo. Ya seas diseñador, ingeniero o aficionado, nuestra solución innovadora te permite generar modelos 3D intrincados directamente a partir de tu entrada escrita. Experimenta el futuro del diseño con una conversión fluida de texto a CAD 3D, haciendo que tus ideas creativas cobren vida con tan solo unas pocas palabras.
Find AI tools in YBX
Related Articles
Refresh Articles