Stability AI Amplía las Capacidades de Generación de Imágenes con Stable Diffusion Medium
Most people like

Mejora tus habilidades para resolver problemas con nuestra innovadora extensión de navegador que ofrece retroalimentación instantánea. Experimenta una forma fluida de potenciar tu proceso de toma de decisiones y superar desafíos de manera eficiente.
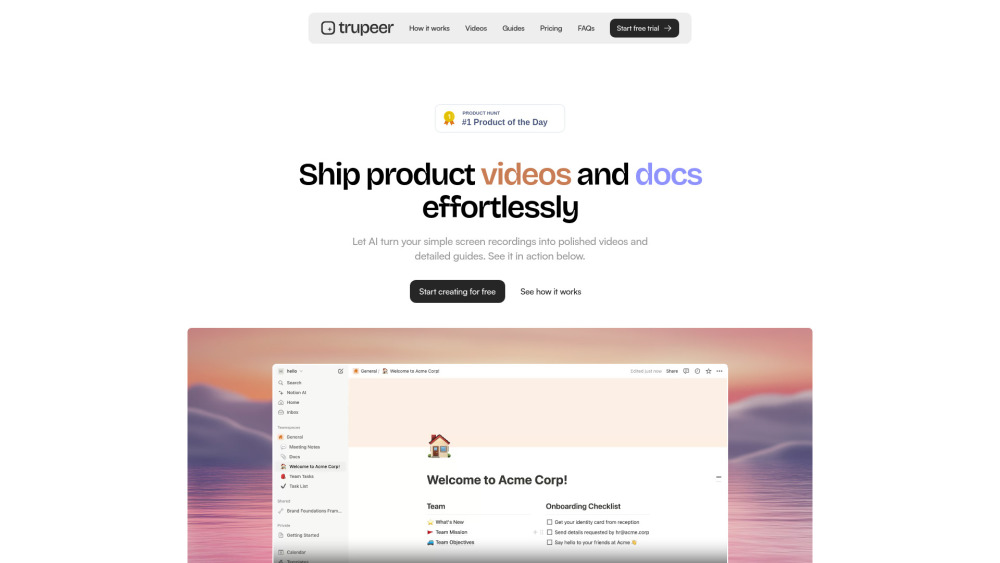
Revoluciona el marketing de tu producto con nuestra plataforma impulsada por IA que transforma grabaciones de pantalla en videos de producto atractivos y documentación completa. Optimiza tu proceso de creación de contenido y mejora la interacción con tu audiencia como nunca antes.
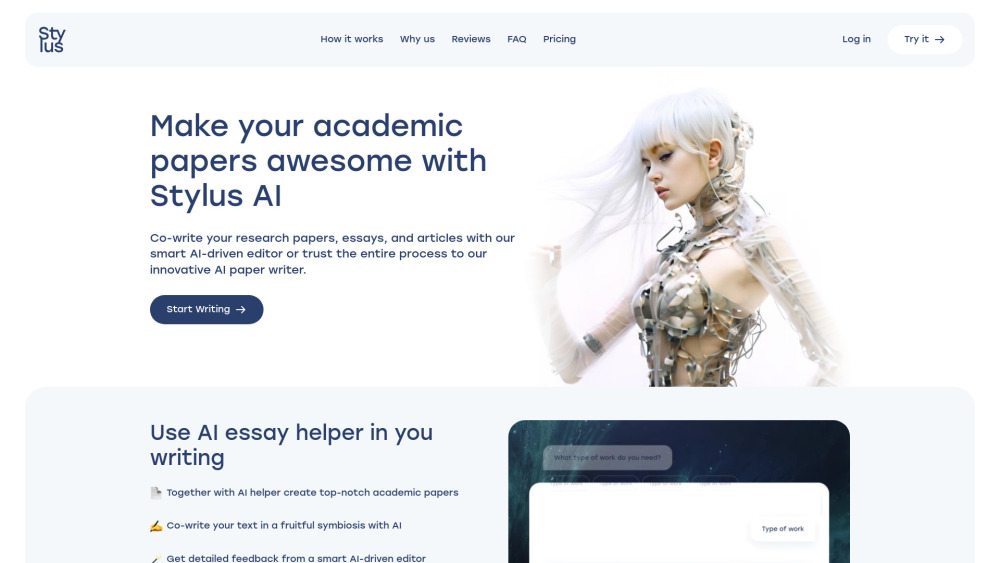
Presentamos nuestra plataforma de IA diseñada específicamente para la redacción, edición e investigación. Esta herramienta innovadora aprovecha el poder de la inteligencia artificial para mejorar tu experiencia de escritura, optimizar el proceso de edición y facilitar investigaciones profundas. Ya seas estudiante, profesional o pensador creativo, nuestra plataforma de IA está aquí para elevar tu viaje en la creación de contenido. Descubre cómo nuestra tecnología puede transformar tus proyectos de escritura con precisión y eficiencia.
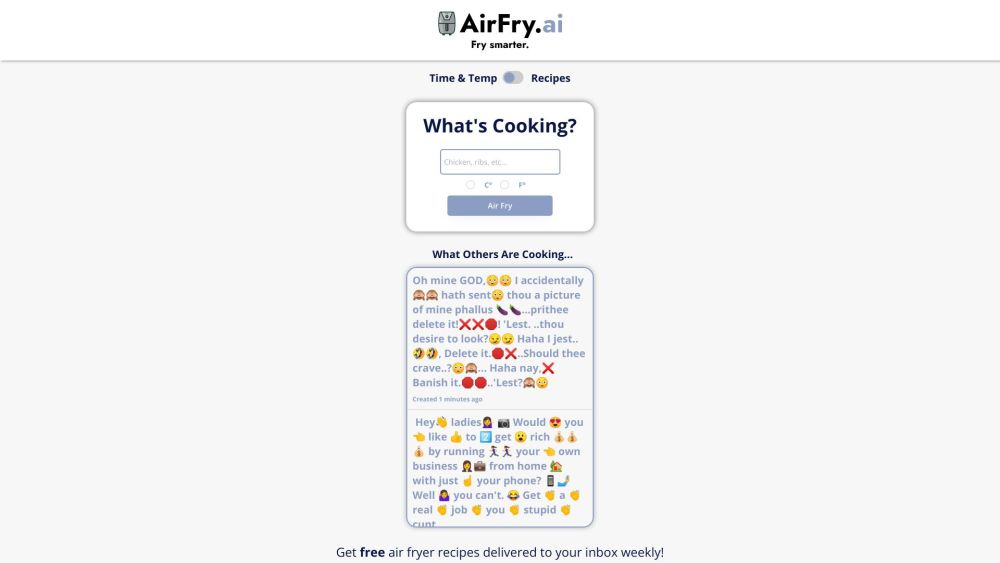
Descubre Air Fry AI, tu recurso ideal para instrucciones y recetas de freidoras de aire, elaboradas con la ayuda de inteligencia artificial.
Find AI tools in YBX
Related Articles
Refresh Articles