GPT-4の力を引き出す:眼科評価における驚異的なパフォーマンスと慎重な実装に向けた専門家の推奨
Most people like
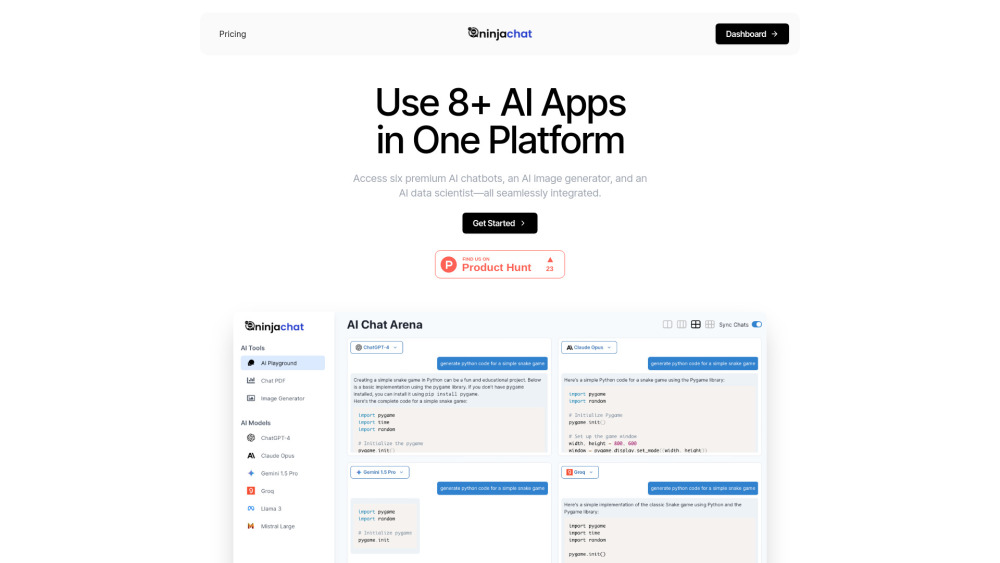
最先端のAIチャットボットプラットフォームを紹介します。ユーザー体験とエンゲージメントを向上させる統合ツールを備えています。私たちの強力なAIソリューションを活用して、顧客とのやり取りを変革し、コミュニケーションをスムーズに統合しましょう。
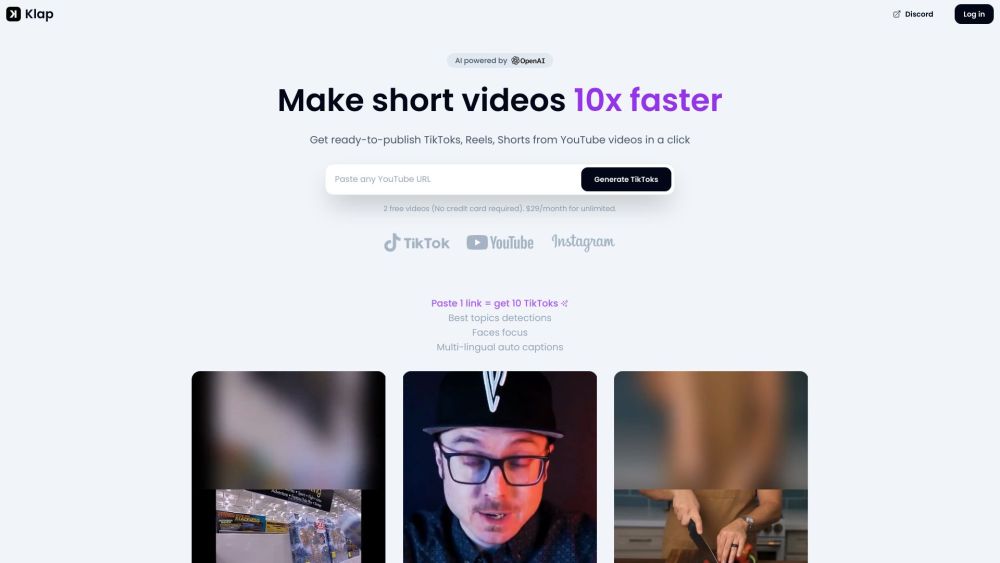
Klapを使用すれば、YouTube動画を簡単に魅力的なTikTokクリップ、YouTube Shorts、Instagram Reelsに変換できます。これは、コンテンツ制作をワンクリックで簡素化する最先端のAIツールです。


URLを変革するAI動画プラットフォーム
今日のデジタル環境では、シームレスなコンテンツ作成と効果的なURL管理の重要性がこれまで以上に高まっています。私たちの革新的なAI動画プラットフォームは、ユーザーが好きな動画をワンクリックで簡単に共有・アクセスできるようにURLを変換することに特化しています。オンラインプレゼンスを強化したいコンテンツクリエイターや、動画マーケティング戦略を最適化したいブランドの皆様に、プロセスを効率化しエンゲージメントを高める最先端のツールを提供します。私たちのAIによるソリューションがどのように動画コンテンツを向上させ、URL変換の取り組みを改善できるか、ぜひご確認ください!
Find AI tools in YBX
Related Articles
Refresh Articles