Microsoftと北京航空航天大学が発表したMoRA:効率的なLLMファインチューニングのための最先端技術
Most people like
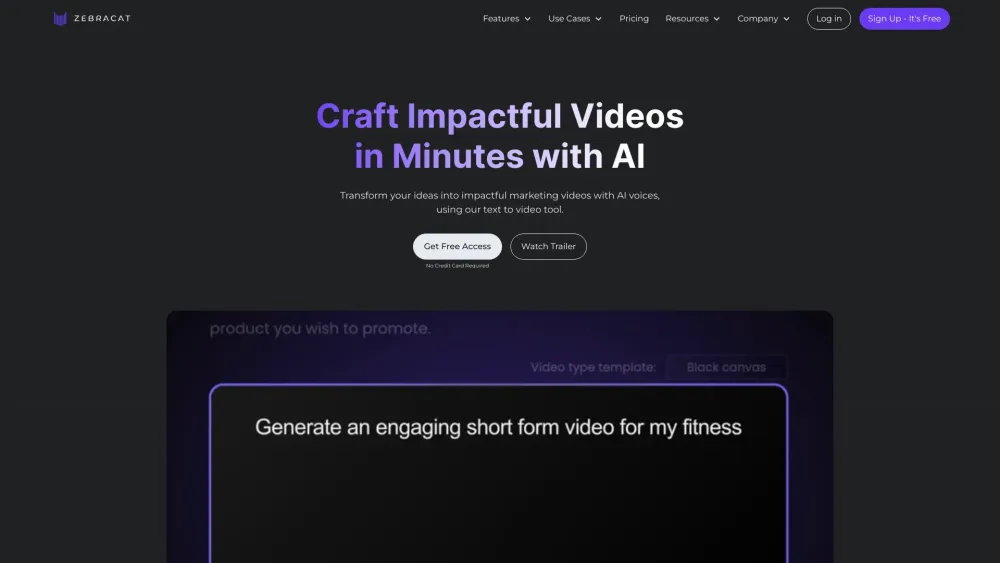
今日のデジタル環境では、効果的なマーケティングには、観客に響く魅力的なビジュアルが不可欠です。AIを活用したマーケティング動画の制作は、高品質なコンテンツの作成プロセスを効率化し、ブランドが視聴者とより効果的に関わることを可能にします。高度なアルゴリズムと機械学習を駆使することで、企業は注目を集めるだけでなく、コンバージョンを促進するカスタマイズされた動画を作成できるようになりました。AI技術がどのように動画マーケティングをブランド成長とオーディエンスとのつながりを促進するダイナミックなツールに変えるのかを探ってみましょう。
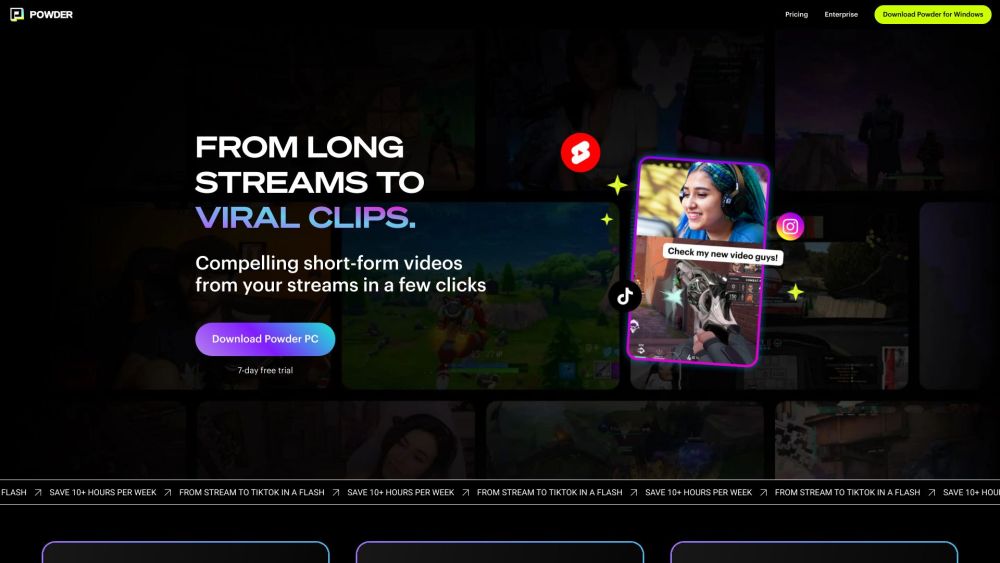

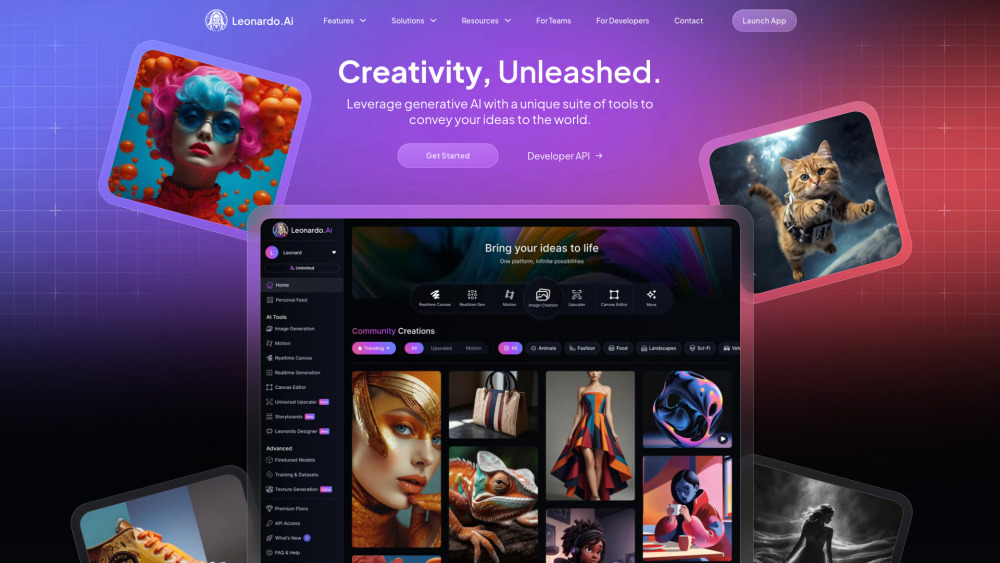
AIによる画像と動画生成の力を活用して、あなたの創造的な取り組みの可能性を引き出しましょう。この革新的な技術により、アーティスト、マーケター、コンテンツクリエイターは、驚くべきビジュアルとダイナミックな動画を簡単に制作できます。AIがどのようにあなたのプロジェクトを高め、物語を豊かにし、観客をこれまでにないほど魅了するかを探求してみましょう。
Find AI tools in YBX
Related Articles
Refresh Articles