도덕적 사고의 강화: OpenAI의 GPT-4o 모델이 윤리 분석에서 인간 전문가를 초월하는 방법
Most people like
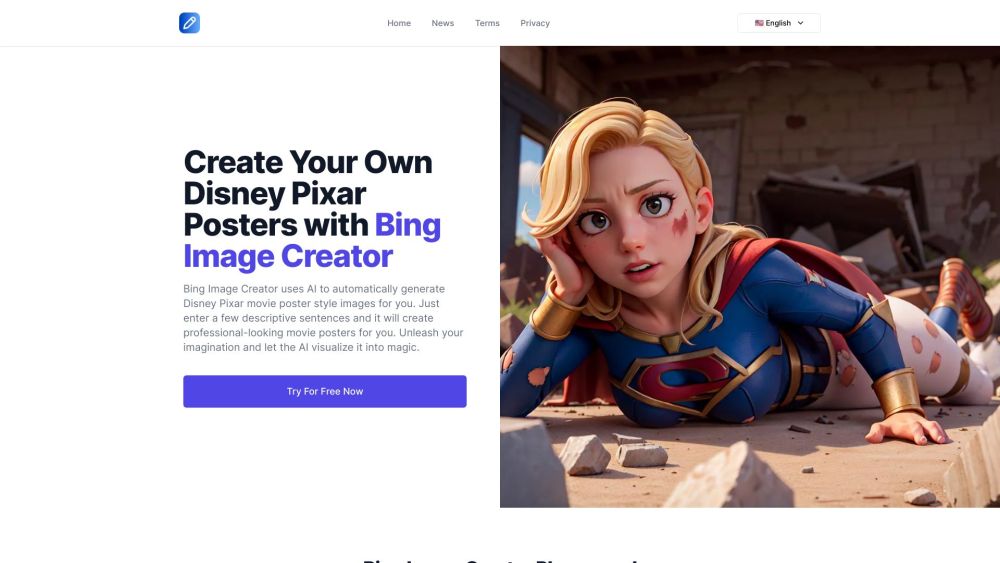
디즈니와 픽사를 위한 AI 기반 영화 포스터 생성 소개: 창의력과 상상력을 발휘하다!
AI 기술로 탄생한 포스터 제작의 혁신적인 세계를 만나보세요. 디즈니와 픽사의 매력적인 세계가 독특하고 시각적으로 매력적인 디자인으로 생동감 있게 표현됩니다. 이 혁신적인 기술은 인공지능을 활용하여 우리가 사랑하는 캐릭터와 이야기를 기념하는 멋진 영화 포스터를 생성합니다. 창의력의 마법에 빠져보고 AI가 클래식 및 새로운 영화 모험을 경험하는 방식을 어떻게 변화시키는지 탐험해보세요!
학생과 작가를 위해 특별히 설계된 최상의 온라인 패러프레이징 도구를 만나보세요. 원래 의미를 유지하며 글을 손쉽게 변형하고 명확성을 향상시킬 수 있습니다. 학술 과제, 창의적인 프로젝트 등 다양한 용도로 완벽합니다!
AI 기반 개념 맵으로 모든 텍스트를 변환하세요. 첨단 기술이 아이디어를 시각화하고 이해를 높이며, 콘텐츠에서 파생된 맞춤형 개념 맵을 통해 학습을 효율화하는 방법을 알아보세요.
Find AI tools in YBX
Related Articles
Refresh Articles