리더보드: OpenAI의 GPT-4, 최소한의 환상을 기록하다.
Most people like
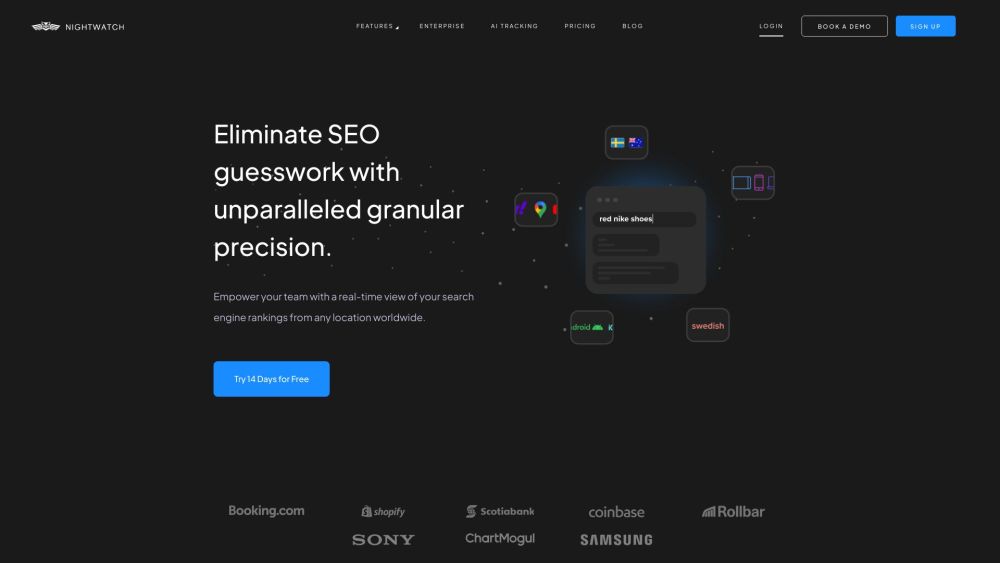
정밀하고 최적화된 키워드 순위를 제공하는 AI 기반 SEO 모니터링 도구를 소개합니다. 끊임없이 변화하는 디지털 환경에서 앞서 나갈 수 있도록 이 혁신적인 솔루션으로 웹사이트 가시성을 최대한 활용하세요.
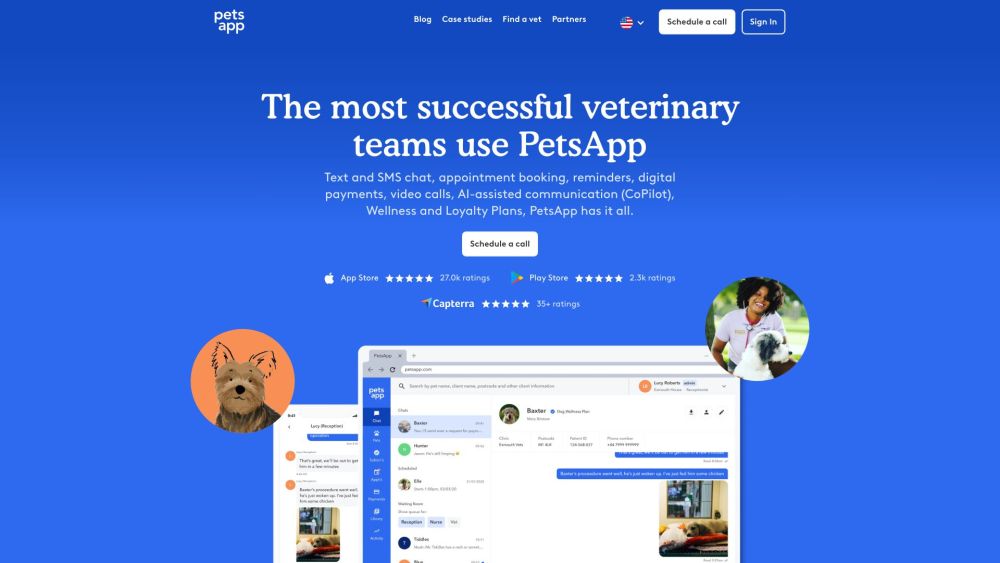
수의사 참여 및 소통을 위한 종합 플랫폼을 소개합니다. 이 플랫폼은 수의사 커뮤니티 내 상호작용을 향상시키도록 설계되었습니다. 혁신적인 이 솔루션은 수의사, 애완동물 주인 및 동물 돌봄 전문가 간의 소통을 원활하게 하고 협업을 촉진합니다.

무한한 AI 생성 사운드의 세계를 발견하세요. 창의성이 무한한 곳입니다. 음악가, 콘텐츠 제작자, 사운드 디자이너를 영감을 주기 위해 맞춤화된 다양한 오디오 경험을 활용해 보세요. 프로젝트를 위한 독특한 사운드스케이프나 비디오를 위한 혁신적인 사운드 효과를 찾고 계시다면, 우리의 최첨단 AI 기술이 무한한 가능성을 제공합니다. 지금 바로 사운드 창작의 미래를 탐험해 보세요!
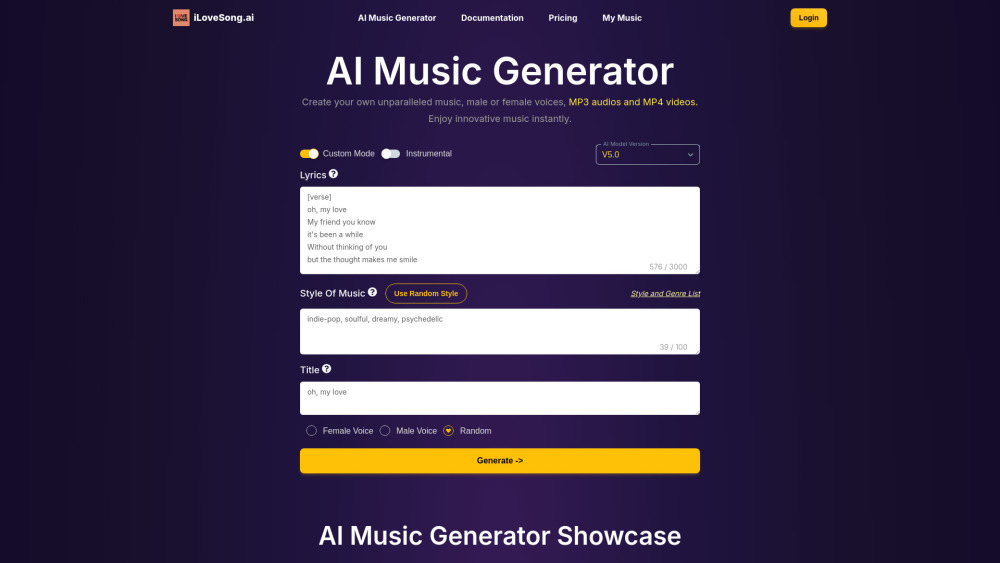
우리의 AI 음악 생성기의 힘을 발견하세요. 이 도구는 여러분의 필요에 맞게 독특하고 맞춤화된 음악을 만들고 다운로드하는 데 도움을 줍니다. 프로젝트를 위한 원작 작곡, 동영상 배경 음악, 또는 개인화된 사운드스케이프를 찾고 계시다면, 우리 플랫폼은 모든 사람이 음악 창작의 예술을 쉽게 즐길 수 있도록 합니다. 오늘부터 여러분만의 멜로디를 만들어보세요!
Find AI tools in YBX
Related Articles
Refresh Articles