유튜브 CEO의 OpenAI에 대한 경고: 비디오 콘텐츠를 이용한 AI 모델 훈련 시 규정 위반의 위험성
Most people like
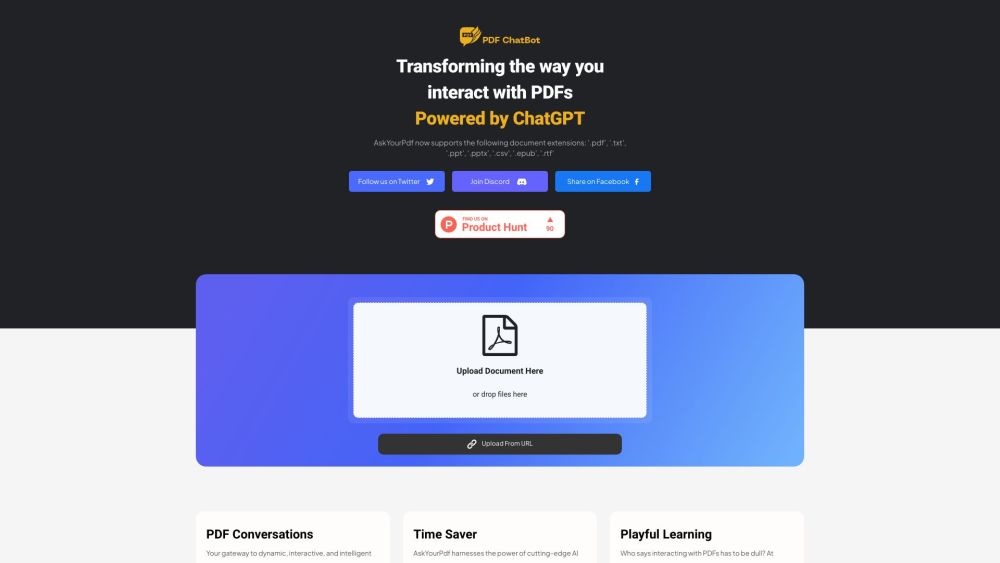
AskYourPDF를 소개합니다. 업로드된 PDF 문서에서 유용한 통찰을 손쉽게 추출할 수 있도록 설계된 혁신적인 AI 채팅 앱입니다. 이 강력한 도구가 복잡한 정보를 명확하고 실행 가능한 지식으로 변화시켜 귀하의 생산성을 어떻게 향상시킬 수 있는지 알아보세요.
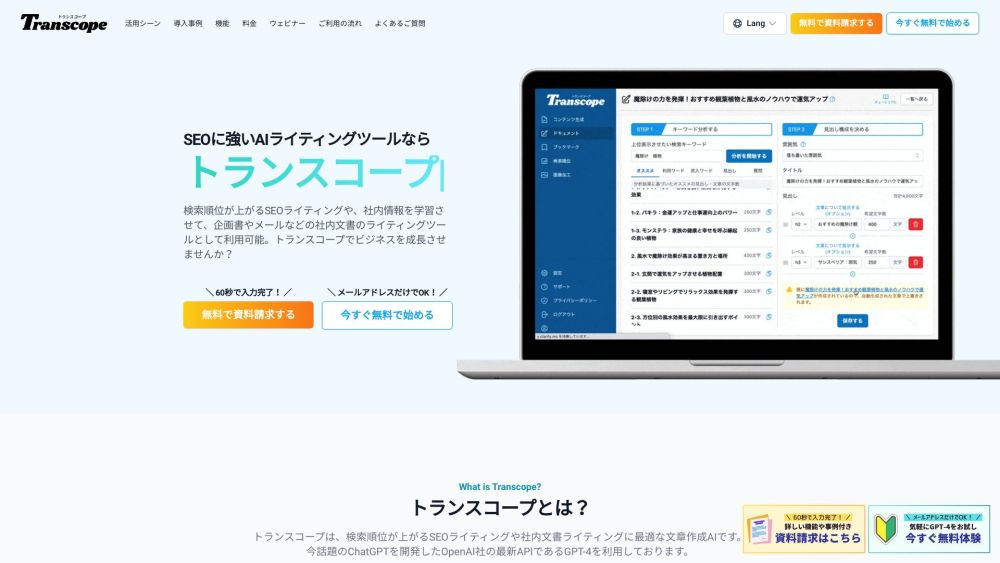
트랜스코프는 GPT-4를 기반으로 한 최첨단 AI 글쓰기 도구로, 고품질의 SEO 최적화된 콘텐츠를 손쉽게 생성할 수 있도록 도와줍니다. 트랜스코프와 함께 고급 글쓰기 기술의 잠재력을 발휘하여 온라인 존재감을 더욱 향상시키세요.

펑슈이 에너지를 활용하여 조화롭고 번영하는 삶을 살 수 있는 방법을 알아보세요. 이러한 원칙을 이해하고 적용함으로써, 여러분의 생활 공간을 평화와 긍정적인 에너지원으로 바꿀 수 있습니다.
Find AI tools in YBX
Related Articles
Refresh Articles