중국의 DeepSeek Coder: GPT-4 Turbo보다 성능이 뛰어난 최초의 오픈소스 코딩 모델
Most people like
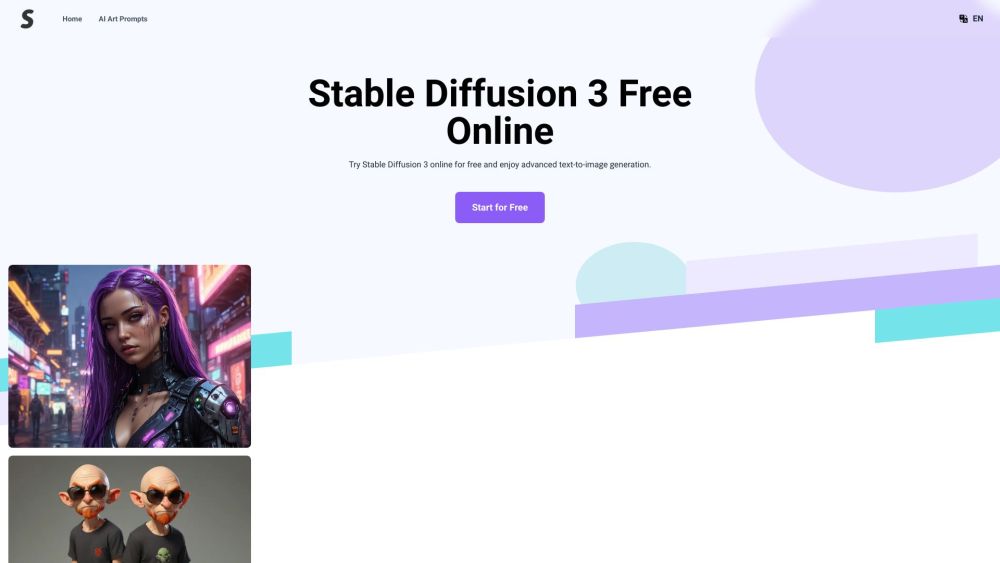
최근 몇 년 동안, 고급 텍스트-이미지 모델의 출현은 인공지능 및 창의적 콘텐츠 생성 분야에 혁신을 가져왔습니다. 이 정교한 시스템은 심층 학습 기법을 활용하여 텍스트 설명을 놀라운 시각적 표현으로 변환합니다. 언어와 맥락의 뉘앙스를 이해함으로써, 이 모델들은 예술가, 마케터, 창작자들이 아이디어를 동적으로 실현할 수 있도록 돕습니다. 이 기사에서는 텍스트-이미지 기술의 메커니즘, 응용 프로그램 및 미래 가능성을 탐구하며, 다양한 산업과 창의적 관행에 미친 영향을 다룹니다.
오늘날 빠르게 변화하는 의료 환경에서, 의료 이미지 분석과 인공지능(AI)의 융합은 진단 및 치료 계획에 혁신을 가져오고 있습니다. 이 분야의 선두주자로서 우리는 정교한 이미징 기법과 AI 기반 통찰력을 통해 환자 결과를 향상시키는 데 전념하고 있습니다. 우리의 선구적인 노력은 기술을 발전시키는 것에 그치지 않고, 의학의 치료 기준을 재정의하며, 정밀 의료의 추구에서 중요한 초석이 되고 있습니다. 우리의 획기적인 혁신이 의료 이미징의 미래를 어떻게 형성하고 있으며, 의료 시스템 전반의 효율성을 어떻게 향상시키고 있는지 알아보세요.
다가오는 이사에 대한 걱정이 크신가요? 저희 AI 기반 이사 도우미는 이사 과정을 간소화하여 더 쉽고 효율적으로 만들어 드립니다. 이사 업무를 정리하는 것부터 귀하의 필요에 맞는 최상의 서비스를 찾는 것까지, 저희 스마트 플랫폼은 모든 단계에서 개인화된 지원을 제공합니다. 이사할 때의 혼란을 뒤로하고, 저희 혁신적인 AI 기술로 보다 매끄럽고 즐거운 경험을 만나보세요. 저희가 귀하의 이사를 원활한 전환으로 만들어 드리겠습니다.

Find AI tools in YBX
Related Articles
Refresh Articles