AI 모델, 자기 안전성 평가: OpenAI 최신 정렬 연구의 통찰력
Most people like

오늘날의 디지털 환경에서 독자의 공감을 얻는 콘텐츠를 만드는 것은 그 어느 때보다 중요합니다. AI 텍스트 변환 기술은 writers가 매력적이고 인간적인 서사를 쉽게 창작할 수 있도록 해주는 강력한 도구로 부상하고 있습니다. 고급 알고리즘과 자연어 처리를 활용하여 AI는 명확성, 톤, 창의성을 향상시켜 콘텐츠 제작자가 청중과 효과적으로 연결될 수 있도록 합니다. AI 기반 텍스트 변환이 당신의 글쓰기 과정을 혁신하고 콘텐츠를 새로운 차원으로 끌어올릴 수 있는 방법을 알아보세요.
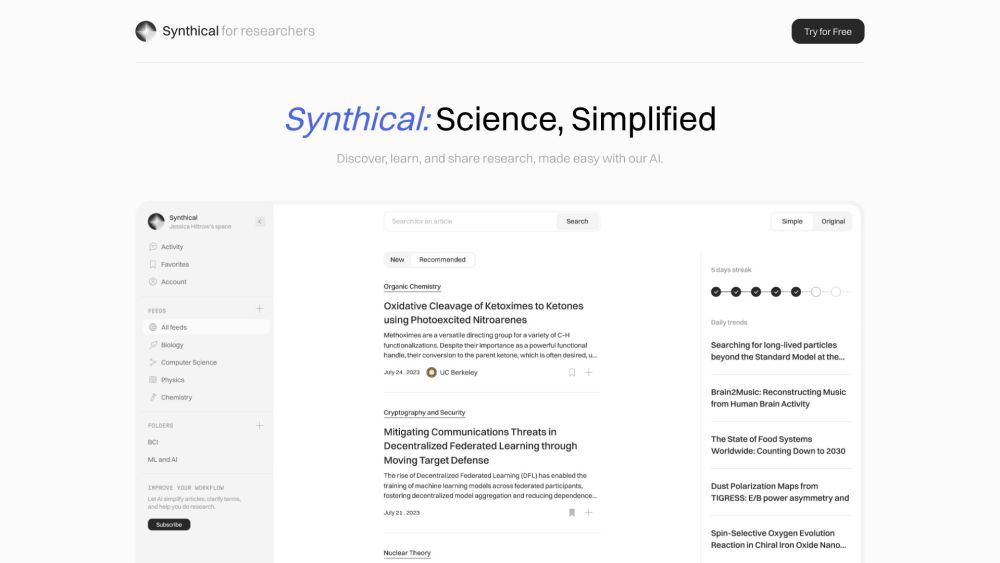
Synthical은 다양한 출처의 최신 콘텐츠를 제공하여 과학 연구의 효율성을 높입니다. 효율성과 접근성을 중시하는 Synthical은 연구자들이 여러 분야에서 최신 발견과 통찰을 쉽게 접할 수 있도록 지원합니다.
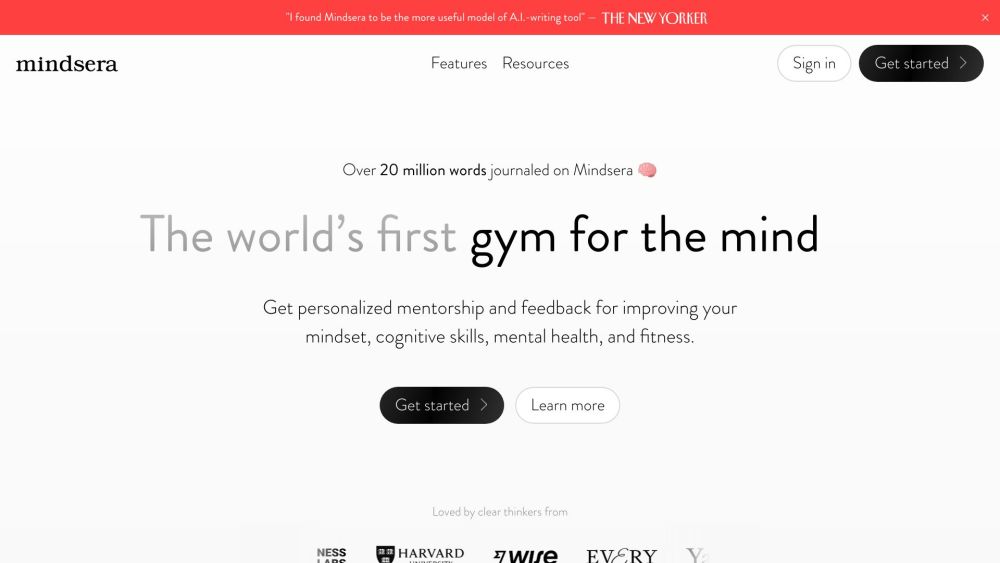
세계 최초의 AI 기반 저널을 소개합니다: 우리의 생각, 아이디어, 경험을 기록하는 방식을 혁신적으로 변화시키는 획기적인 혁신입니다. 이 최첨단 도구는 인공지능을 활용하여 자기 반성을 증진하고, 체계를 개선하며, 저널링 여정을 개인화합니다. 이 혁신적인 저널이 어떻게 일상적인 글쓰기 연습을 향상시키고 정신 건강을 지원할 수 있는지 알아보세요.
신경과학의 잠재력을 활용하여 소비자 반응에 대한 깊은 통찰을 얻으세요. 최첨단 뇌 과학 기법을 이용함으로써 기업들은 고객의 사고 방식과 의사 결정 과정을 보다 잘 이해할 수 있어, 더욱 효과적인 마케팅 전략과 향상된 제품 개발로 이어집니다. 소비자 행동을 정밀하게 예측하여 경쟁 우위를 확보하세요.
Find AI tools in YBX
Related Articles
Refresh Articles