LLaVA++ 프로젝트의 주요 breakthroughs: Phi-3 및 Llama-3 모델의 시각적 능력 강화
Most people like

펑슈이 에너지를 활용하여 조화롭고 번영하는 삶을 살 수 있는 방법을 알아보세요. 이러한 원칙을 이해하고 적용함으로써, 여러분의 생활 공간을 평화와 긍정적인 에너지원으로 바꿀 수 있습니다.
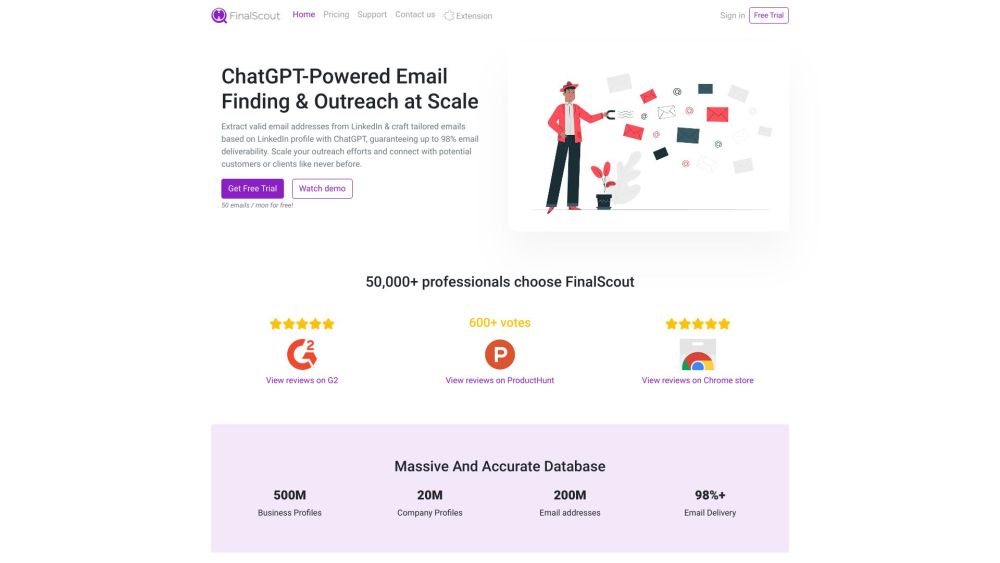
LinkedIn 이메일 추출의 힘을 활용하고 ChatGPT를 통해 맞춤형 아웃리치 전략을 이용하세요. 네트워킹 수준을 높이고 목표 고객과 효과적으로 연결하세요!
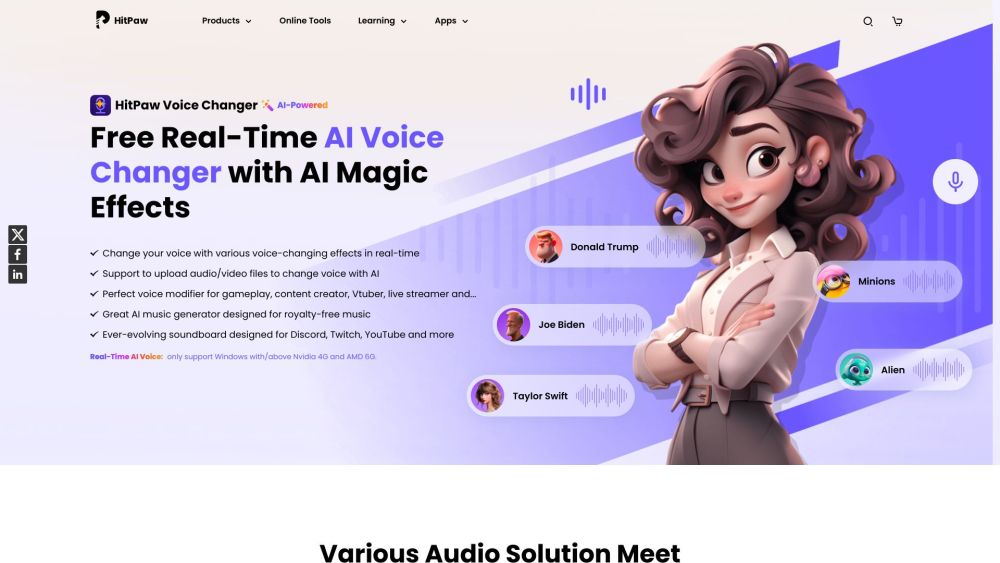
실시간 AI 음성 변환기로 음성을 즉시 변환하세요. 다양한 놀라운 효과를 제공하여 매끄러운 음성 변조를 경험하고 오늘날 당신의 오디오 창의력을 높여보세요!
Find AI tools in YBX
Related Articles
Refresh Articles