Stable Diffusion 3.0이 차세대 텍스트-이미지 AI 생성의 혁신적인 확산 아키텍처를 출시합니다.
Most people like
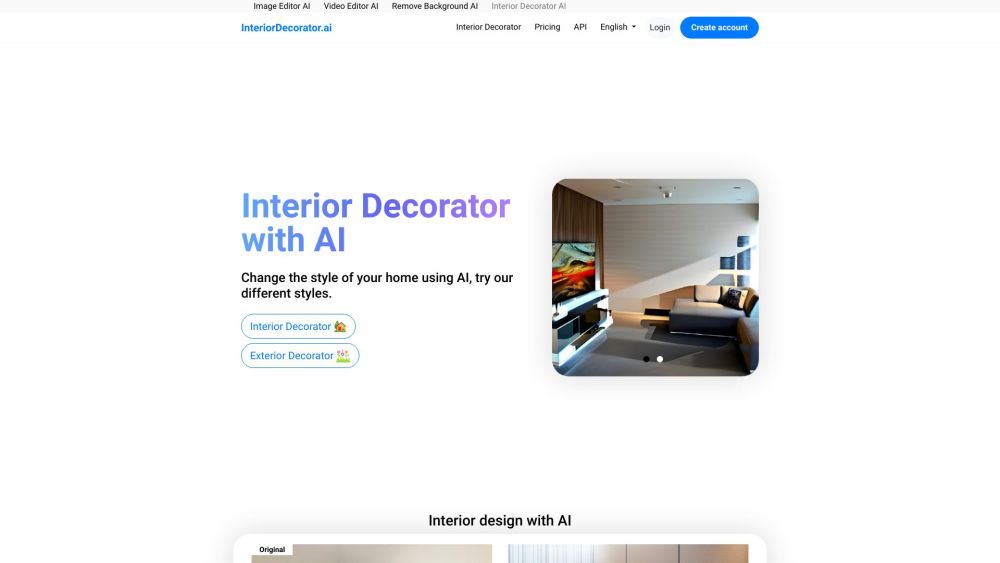
InteriorDecorator.ai에 오신 것을 환영합니다. 혁신적인 AI 플랫폼으로, 귀하의 집을 위한 맞춤형 인테리어 디자인 아이디어를 제공합니다. 첨단 AI 알고리즘을 활용하여, 귀하의 생활 공간을 한층 높여줄 독창적인 장식 제안을 드립니다. 오늘 저와 함께 미래의 홈 디자인을 탐험해보세요!


우리의 AI 인사이트 플랫폼에 오신 것을 환영합니다. 이 플랫폼은 인공지능의 힘을 활용하려는 창작자와 기업을 위해 특별히 설계되었습니다. 유용한 데이터 기반 인사이트를 제공하여 사용자가 창의성을 향상시키고, 의사 결정을 개선하며, 성장을 촉진할 수 있도록 지원합니다. AI가 귀하의 프로젝트와 전략을 어떻게 변모시킬 수 있는지 알아보아, 오늘날의 치열한 경쟁 환경에서 성공을 거둘 수 있는 길을 열어보세요. 우리의 기능을 탐색하여 잠재력을 최대한 발휘하세요!

Glean은 팀을 위해 설계된 혁신적인 검색 솔루션으로, 중요한 정보와 필수 지식을 손쉽게 찾을 수 있도록 도와줍니다. 프로젝트 협업이나 업무 관리 시, Glean은 팀이 필요한 정보를 신속하게 접근할 수 있는 능력을 향상시킵니다.
Find AI tools in YBX
Related Articles
Refresh Articles