구글의 DataGemma AI의 힘을 열어보세요: 최고의 통계 마법사
Most people like
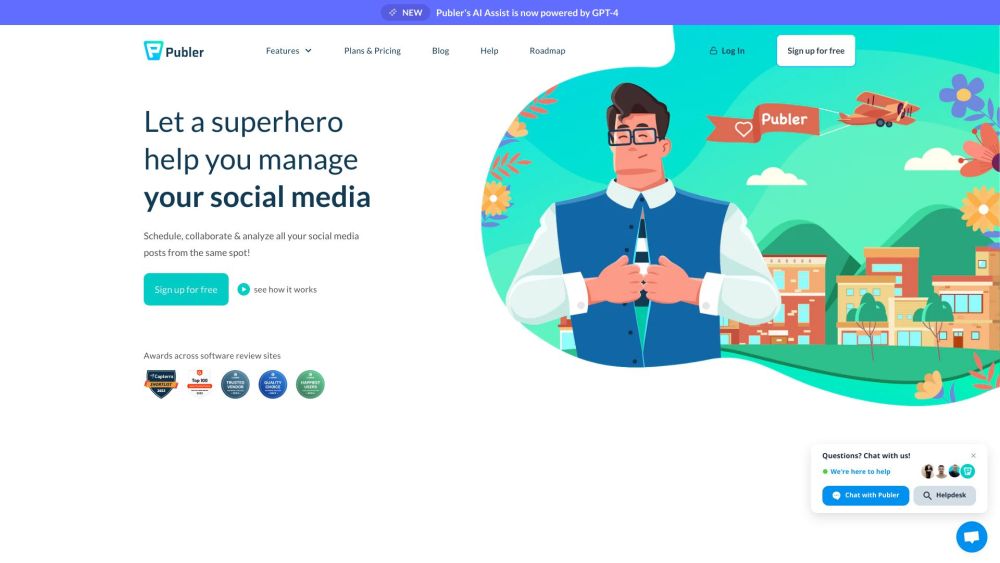
Publer는 다양한 플랫폼에서 소셜 미디어 게시물을 효율적으로 일정 관리하고 분석하기 위해 설계된 직관적인 도구입니다. 사용자 친화적인 인터페이스와 강력한 기능을 갖춘 Publer는 소셜 미디어 전략 관리를 간소화하여 시간을 절약하고 참여도를 높입니다.
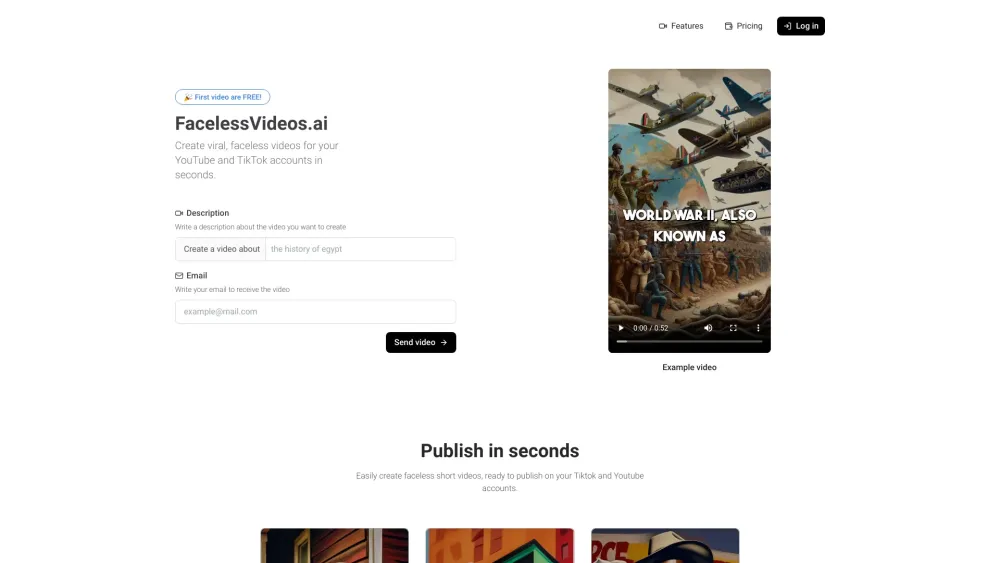
AI 기술로 얼굴 없는 TikTok 영상의 세계를 열어보세요! 이 가이드에서는 시청자를 사로잡는 매력적이고 익명성 있는 콘텐츠를 쉽게 제작하는 방법을 알아볼 수 있습니다. 카메라 앞에서의 불안은 잊고 무한한 창의력의 잠재력을 만나보세요. 오늘날 AI가 여러분의 TikTok 존재감을 어떻게 변화시킬 수 있는지 알아보세요!
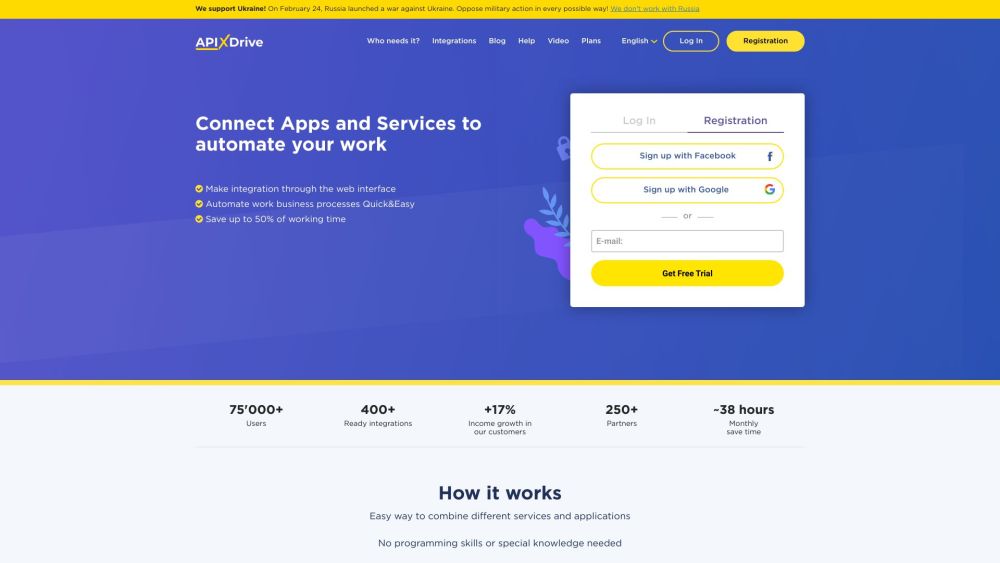
코딩 기술 없이 손쉽게 작업을 자동화하세요! 누구나 사용할 수 있는 간단한 자동화 도구로 워크플로를 간소화하고 생산성을 높이는 방법을 알아보세요. 시간이 절약되고 일상 업무의 효율성이 향상되는 노코드 솔루션의 힘을 활용해 보세요.
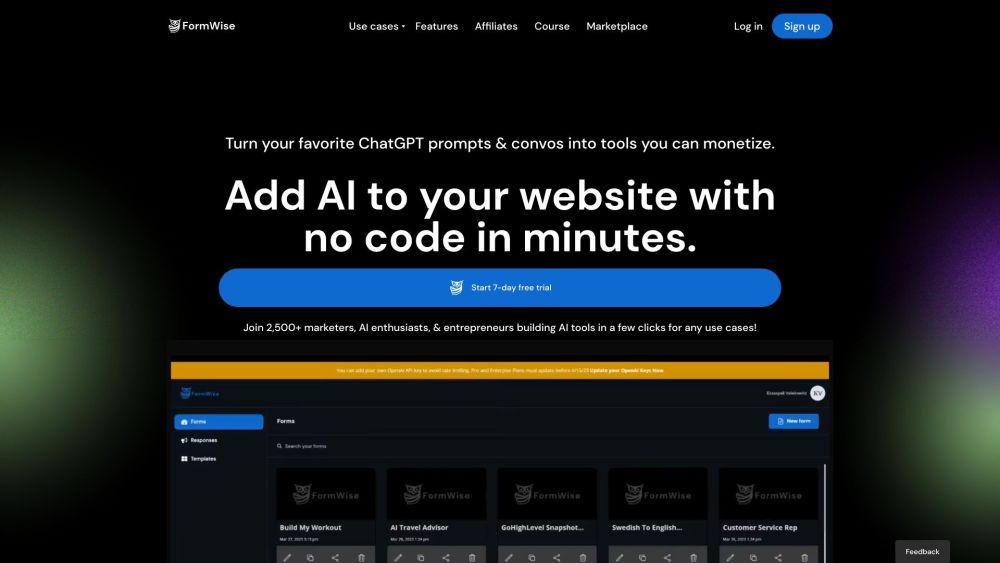
Find AI tools in YBX
Related Articles
Refresh Articles