메타, 오디오, 텍스트 및 워터마크 혁신을 위한 새로운 AI 모델 공개
Most people like
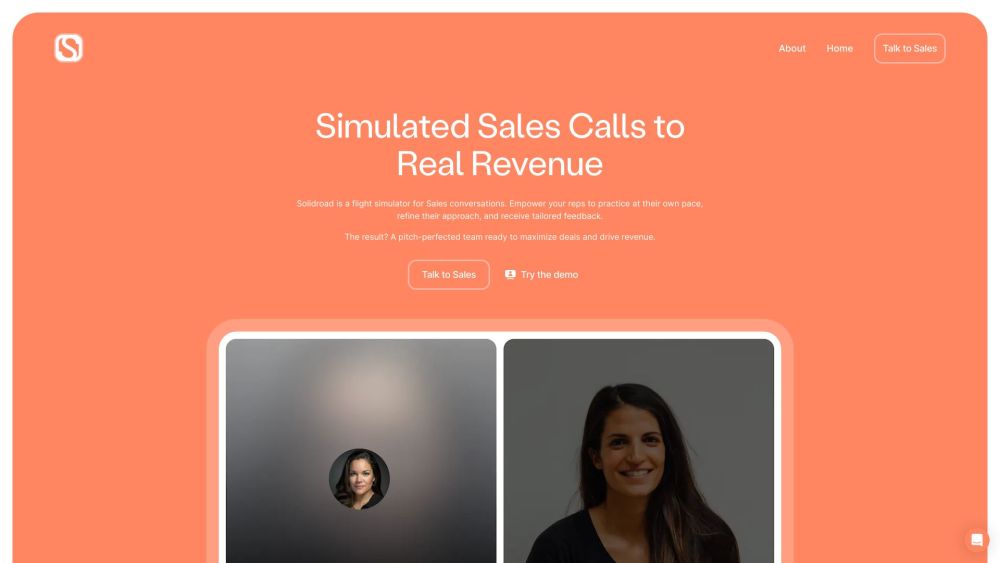
판매 전화를 위해 특별히 설계된 AI 대화 시뮬레이터로 판매 전략을 강화하세요. 이 혁신적인 도구는 판매 전문가가 기술을 연습하고 다듬을 수 있도록 도와주며, 모든 상호작용이 매력적이고 설득력 있게 만들도록 합니다. 판매 접근 방식을 혁신하고 최첨단 AI 기술로 효과적인 커뮤니케이션의 영향을 경험해 보세요.

온라인 콘텐츠를 손쉽게 요약하고 저장하기
오늘날의 빠르게 변화하는 디지털 세계에서 온라인 콘텐츠 관리는 어려울 수 있습니다. 웹 콘텐츠를 효율적으로 요약하고 저장하는 방법을 통해 경험을 간소화해 보세요! 연구, 학습 또는 정보를 선별하는 과정에서 이 기술을 숙달하면 생산성을 높이고 작업 흐름을 원활하게 할 수 있습니다. 콘텐츠 관리를 쉽게 할 수 있는 최선의 방법을 살펴보겠습니다.
Find AI tools in YBX
Related Articles
Refresh Articles