새로운 기술 무기 경쟁: 첨단 AI 개발을 위한 10억 달러의 탐험
Most people like

화면 시간을 최소화하면서 지식과 통찰력을 극대화하는 방법을 알아보세요. 긴 비디오에서 정보를 빠르게 이해할 수 있는 효과적인 전략을 배우고, 더 적게 시청하면서도 더 효율적으로 학습할 수 있습니다.
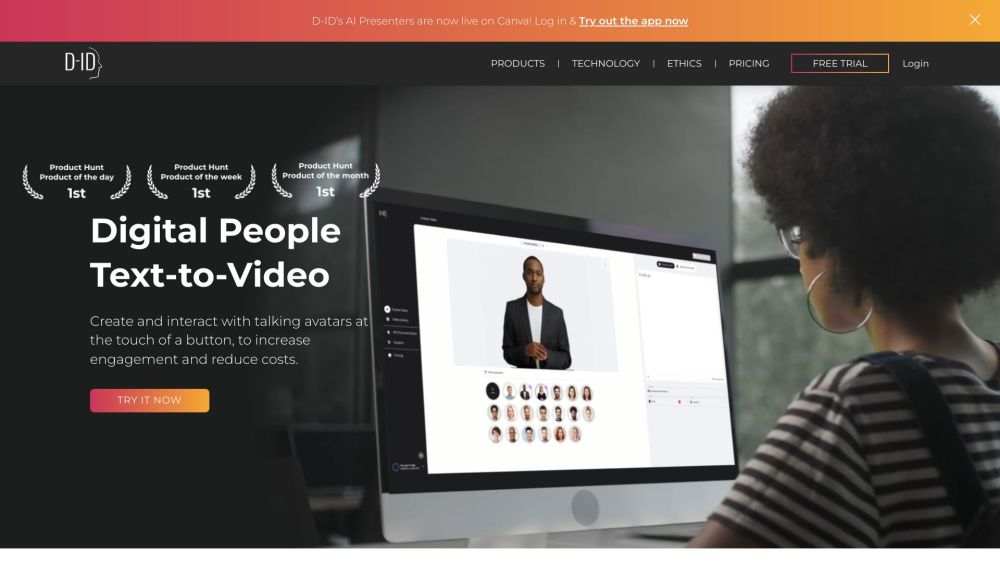
D-ID는 사진과 텍스트를 매력적인 비디오로 변환하는 혁신적인 AI 플랫폼입니다. 첨단 기술을 바탕으로 D-ID는 사용자들이 쉽게 동적인 시각 콘텐츠를 생성하여 효과적으로 소통할 수 있도록 돕습니다.
AI 기반 콘텐츠 작성 플랫폼의 혁신적인 잠재력을 발견해 보세요. 첨단 인공지능을 활용하여 콘텐츠 제작을 간소화하며, 높은 품질의 기사, 블로그 포스트 및 마케팅 카피를 쉽게 작성할 수 있습니다. 경험이 풍부한 작가든 바쁜 직장인이든 관계없이, 이 플랫폼은 독창적인 목소리를 유지하며 신속하게 매력적인 콘텐츠를 생성할 수 있도록 도와줍니다. 최신 AI 기술로 오늘 당신의 글쓰기 경험을 향상시켜 보세요!
Mailchimp의 강력한 마케팅 및 자동화 플랫폼으로 고객 전환율을 높이세요. 효율적으로 노력을 조정하고 대중과 소통하여 판매를 촉진하고 비즈니스를 성장시키세요.
Find AI tools in YBX
Related Articles
Refresh Articles