애플의 혁신적인 AI 연구, 합리적인 가격으로 높은 성능 제공
Most people like
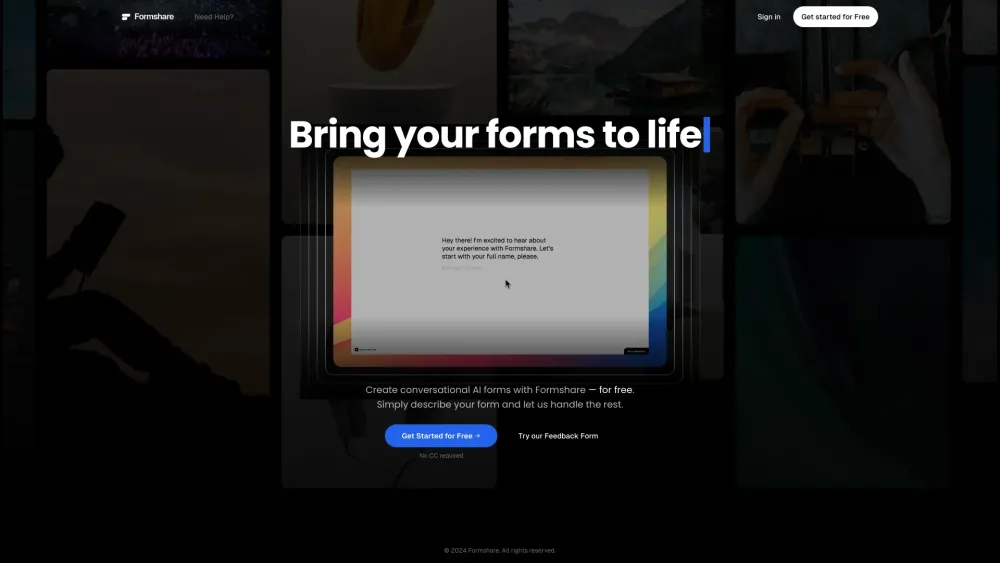
오늘날의 디지털 환경에서 맞춤형 양식을 신속하게 생성하는 능력은 기업에 필수적입니다. 고급 AI 도구를 활용하면 코딩 지식 없이도 쉽게 지능형 양식을 설계할 수 있습니다. 이 사용자 친화적인 접근 방식은 기업가부터 마케터까지 누구나 데이터 수집을 간소화하고 사용자 경험을 향상시키며 시간과 자원을 절약할 수 있게 합니다. AI 기반 양식 생성을 통해 작업 흐름을 단순화하고 프로젝트를 향상시키는 방법을 발견해 보세요. 기술적 기술과 관계없이 모든 사람이 접근할 수 있습니다.

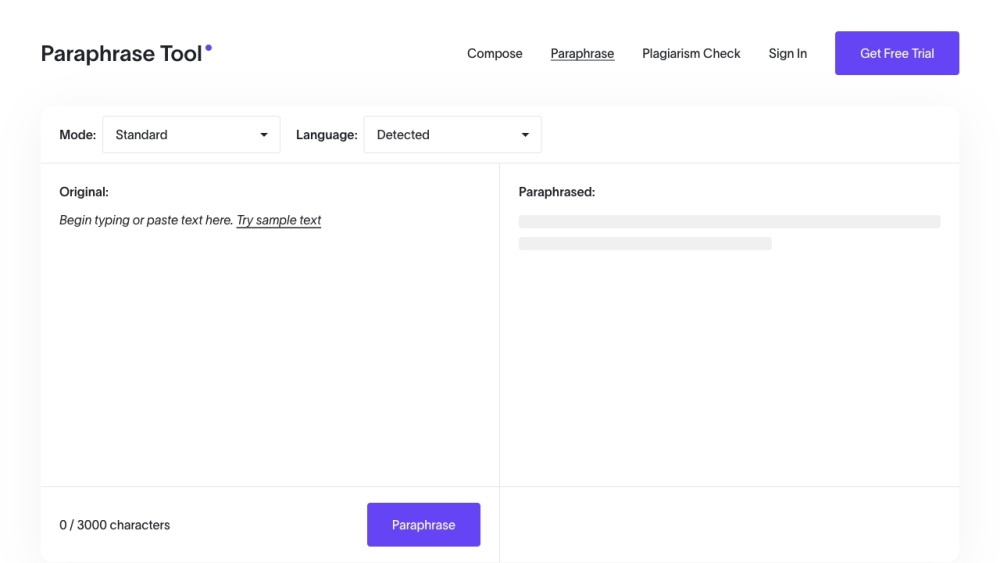
패러프레이즈 도구 소개: 무료 온라인 패러프레이징, 문법 검사 및 표절 제거를 위한 필수 자원. 100개 이상의 언어로 제공되며, 글쓰기의 명확성과 독창성을 손쉽게 향상시킵니다.
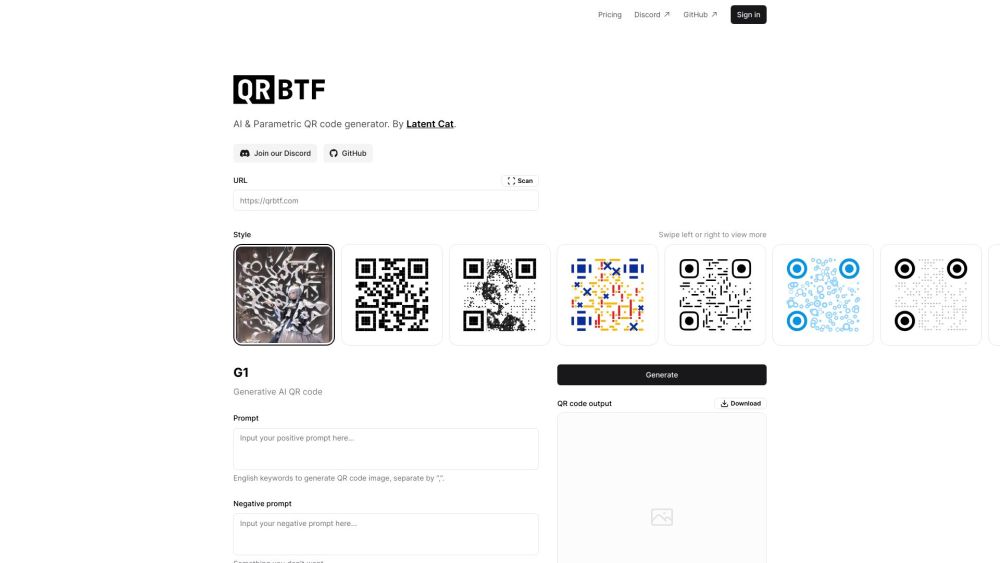
최고의 AI 기반 QR 코드 생성기를 소개합니다—놀랍고 고품질의 QR 코드를 손쉽게 만들 수 있는 첫 번째 선택입니다! 우리의 혁신적인 도구로 마케팅 전략을 강화하고 청중과 소통하세요. 오늘 바로 사용해 보시고 그 간편함과 효과를 직접 경험해 보세요!
Find AI tools in YBX
Related Articles
Refresh Articles