코헤어의 Rerank 3, 기업 검색의 혁신으로 효율성과 인사이트 생성 향상
Most people like
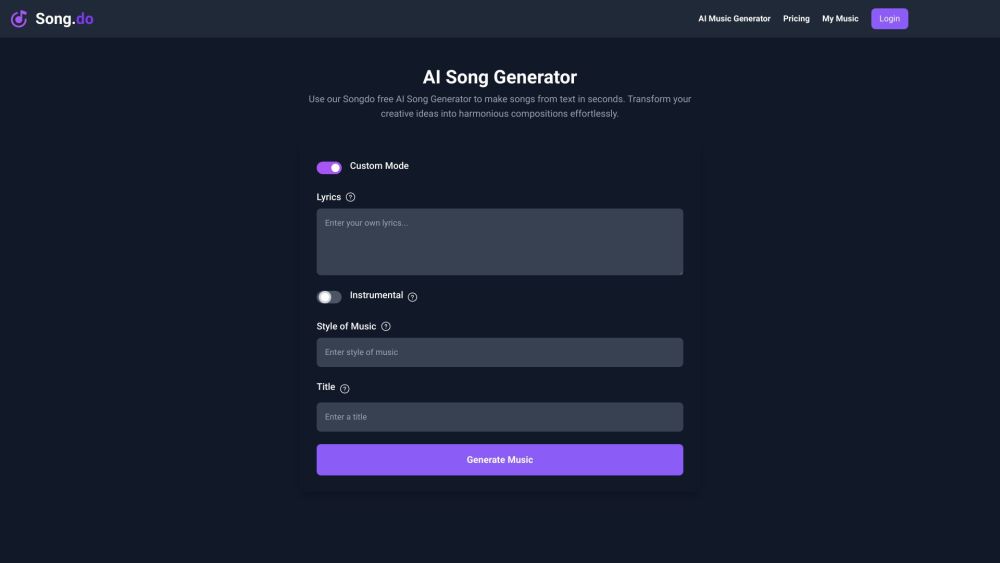
당신의 창의력을 발휘할 수 있는 무료 AI 송 생성기를 만나보세요. 이 도구는 당신의 음악적 아이디어를 매력적인 멜로디로 변환해 줍니다. 작곡가 지망생이든 경험 많은 음악가든, 이 혁신적인 도구는 최신 인공지능 기술을 활용하여 단 몇 분 안에 독창적인 곡을 작곡할 수 있도록 도와줍니다. 음악 제작의 미래를 받아들이고 모든 이를 위해 고안된 사용하기 쉬운 플랫폼에서 무한한 가능성을 탐험해 보세요. 오늘 AI 기반 음악 제작의 세계로 뛰어들어 보세요!
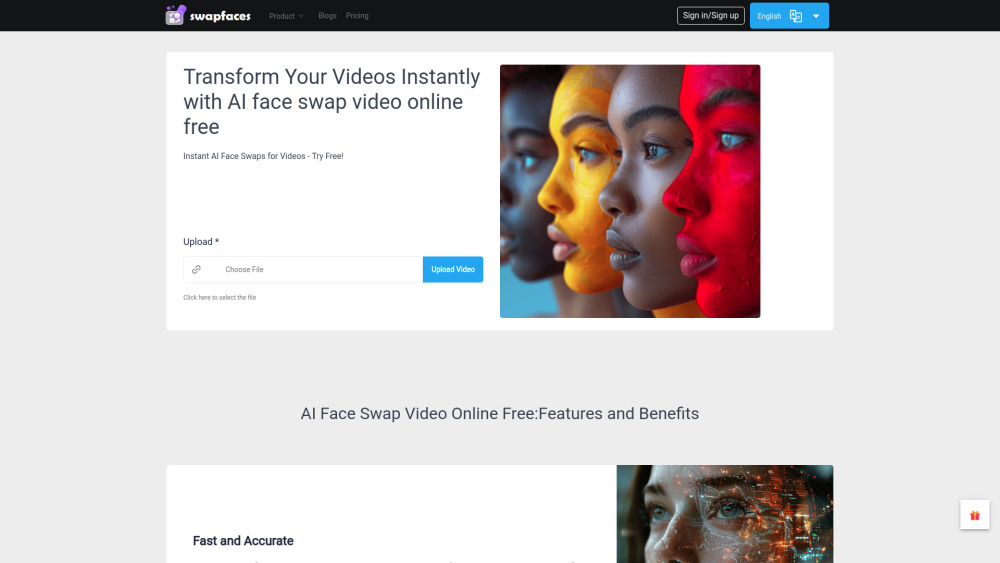
최첨단 AI 기반 비디오 얼굴 전환 도구를 소개합니다. 이 혁신적인 솔루션은 비디오 제작 및 공유 방식을 혁신적으로 변화시킵니다. 몇 번의 클릭만으로 비디오에서 얼굴을 매끄럽게 전환할 수 있어 스토리텔링과 창의적인 프로젝트를 향상시킵니다. 콘텐츠 제작자, 마케터 또는 단순히 재미를 찾는 분 모두에게 최적화된 인터페이스와 고급 알고리즘이 stunning한 비디오 변환을 쉽게 만들어줍니다. 무한한 가능성을 탐험하고 오늘 your 비디오 콘텐츠를 한 차원 높이세요!
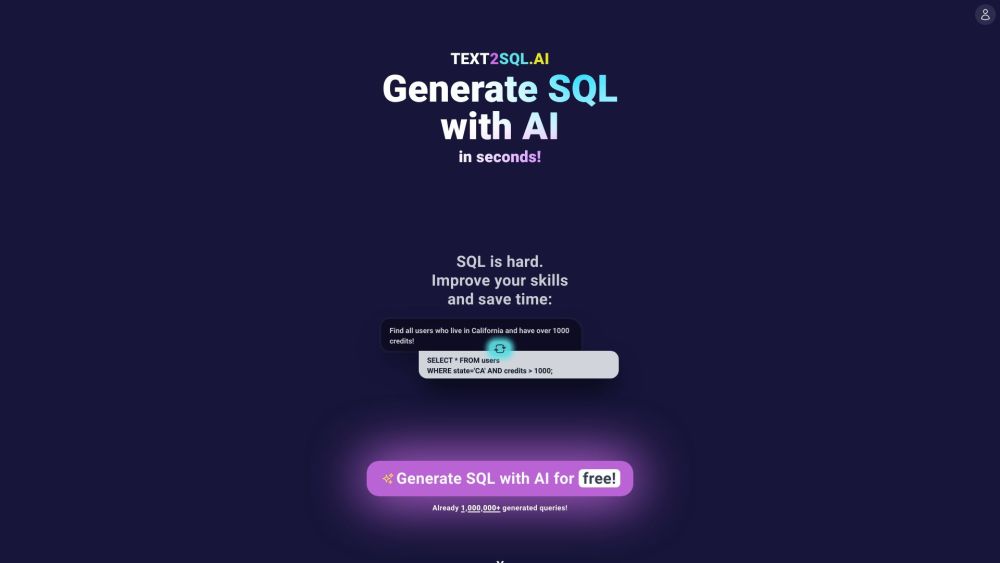
영어 명령어를 손쉽게 SQL 쿼리로 변환하는 사용자 친화적인 AI 플랫폼을 소개합니다. 자연어와 데이터베이스 상호작용 간의 간극을 연결하는 직관적인 도구로 데이터 관리를 효율적으로 간소화하세요.
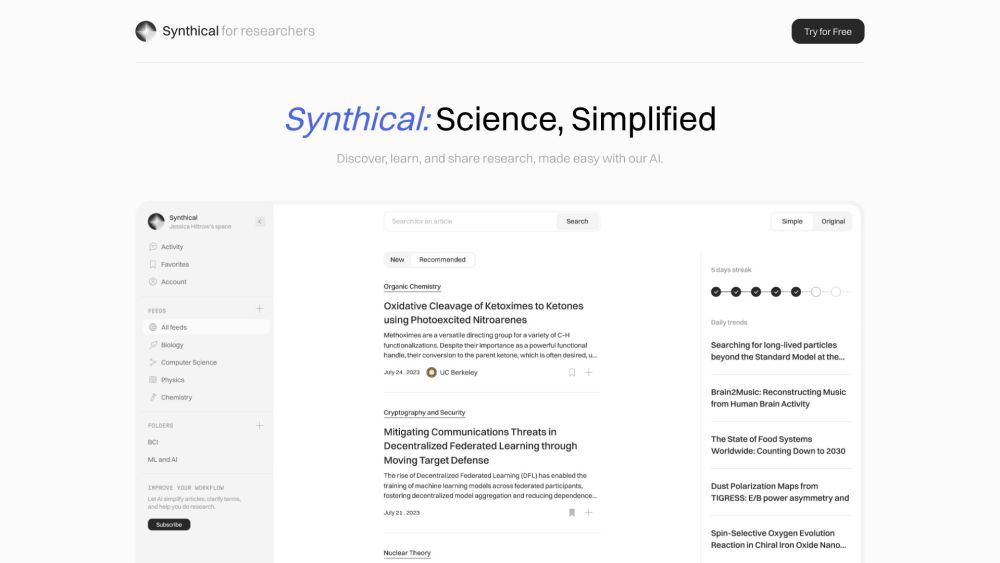
Synthical은 다양한 출처의 최신 콘텐츠를 제공하여 과학 연구의 효율성을 높입니다. 효율성과 접근성을 중시하는 Synthical은 연구자들이 여러 분야에서 최신 발견과 통찰을 쉽게 접할 수 있도록 지원합니다.
Find AI tools in YBX
Related Articles
Refresh Articles