챗봇 허위정보 대응: 구글 딥마인드와 스탠포드 대학, AI 사실 확인 도구 출시
Most people like

AI 던전 마스터와 함께 D&D 5e를 전혀 새로운 방식으로 경험하세요. 혼자서의 모험을 즐기거나 다인용 캠페인에 참여할 수 있으며, 언제 어디서나 편리하게 가능합니다. AI의 힘으로 테이블탑 게임의 무한한 가능성을 발견해 보세요!

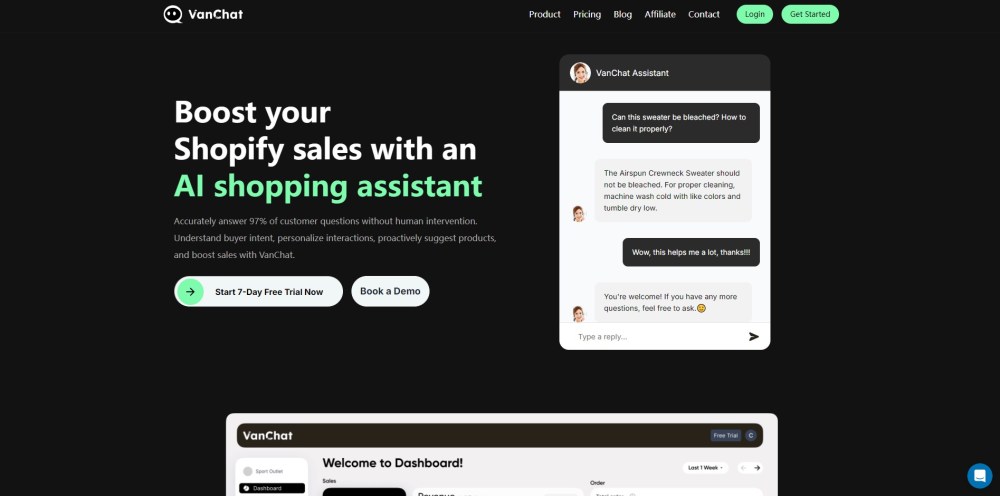
AI 쇼핑 비서가 Shopify에서 고객 상호작용을 어떻게 변화시켜 참여를 유도하고 매출을 증가시킬 수 있는지 알아보세요. 첨단 기술을 활용한 이 혁신적인 도구는 모든 사용자를 위해 쇼핑 경험을 매끄럽고 개인화된 형태로 개선합니다. 고객의 니즈를 이해하는 지능형 비서로 오늘 바로 Shopify 매장을 한 단계 끌어올리세요.
Find AI tools in YBX
Related Articles
Refresh Articles