A Stability AI Expande Capacidades de Geração de Imagem com Stable Diffusion Medium
Most people like
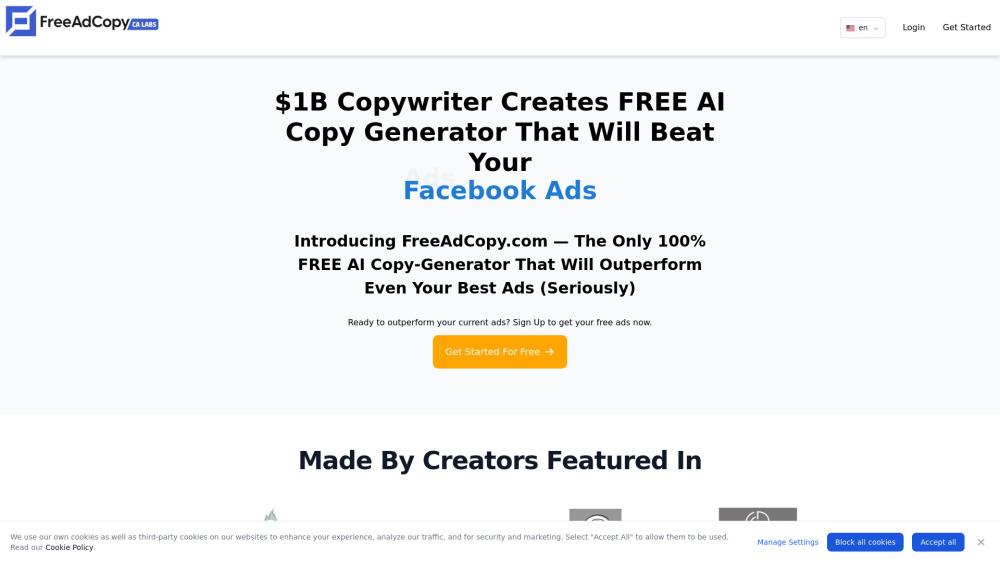
Revolucione sua estratégia de publicidade com nossa ferramenta de IA de ponta, projetada para gerar instantaneamente textos publicitários cativantes. Transforme a forma como você cria conteúdo de marketing, garantindo que sua mensagem ressoe com seu público e economize tempo e esforço. Descubra o poder da inteligência artificial na criação de anúncios eficazes que aumentam o engajamento e potencializam as conversões.
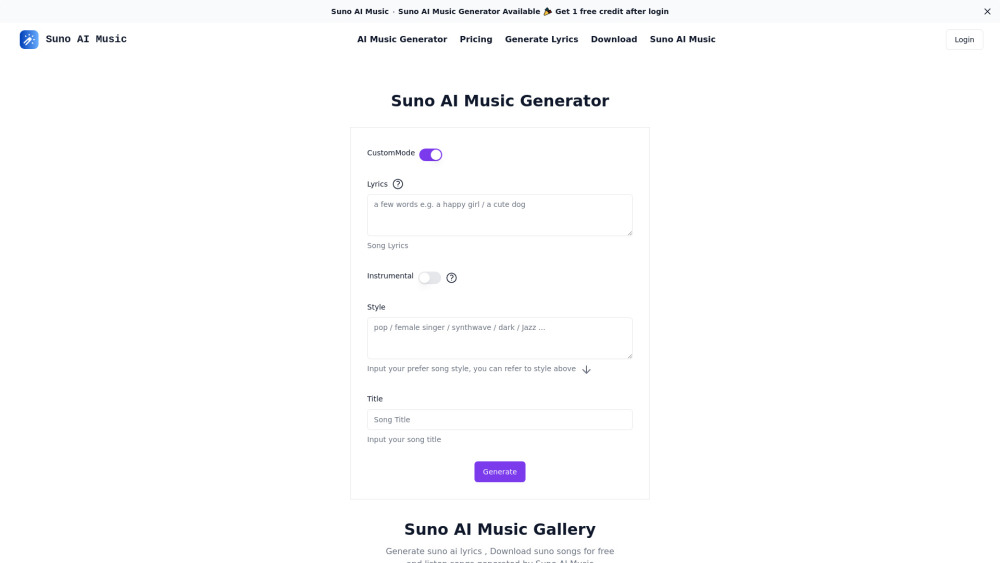
Nos últimos anos, plataformas de geração de música por IA revolucionaram a forma como criamos e interagimos com a música. Essas tecnologias inovadoras utilizam algoritmos avançados e aprendizado de máquina para compor canções, desenvolver paisagens sonoras únicas e auxiliar músicos em seus processos criativos. Ao combinar a criatividade humana com o poder da inteligência artificial, essas plataformas oferecem oportunidades sem precedentes para artistas, produtores e amantes da música, tornando a criação musical mais acessível e inspiradora. Explore o fascinante mundo da geração musical por IA e descubra como está transformando o futuro do som.
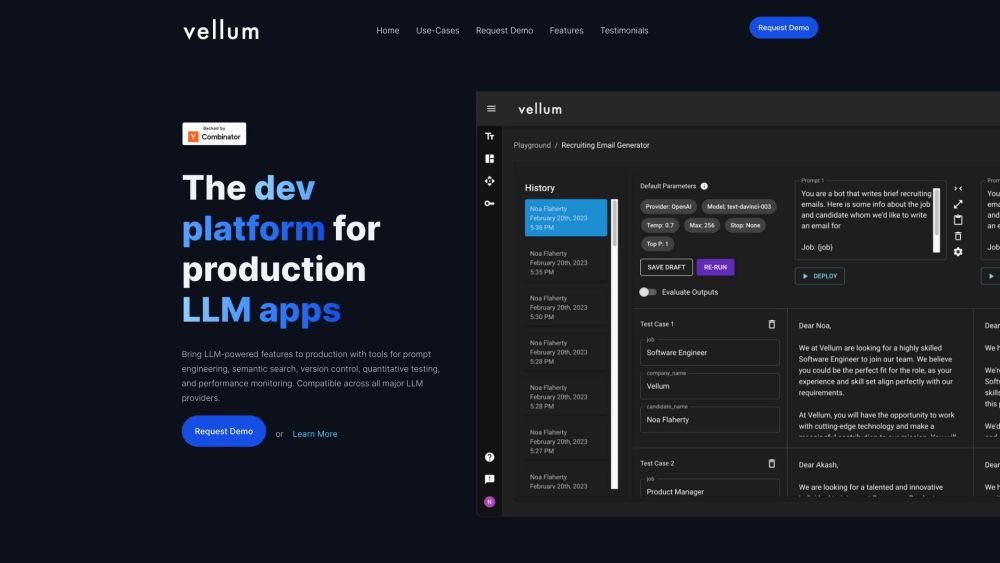
Apresentamos uma plataforma de desenvolvimento de ponta, projetada especialmente para a criação de aplicações de modelos de linguagem de grande escala (LLM). Esta plataforma inovadora torna o processo de desenvolvimento mais ágil, fornecendo aos desenvolvedores as ferramentas e recursos necessários para construir, testar e implantar soluções poderosas baseadas em LLM de forma eficiente. Seja você um desenvolvedor experiente ou esteja apenas começando, nossa plataforma oferece a flexibilidade e o suporte para dar vida às suas ideias de IA. Junte-se a nós na revolução do desenvolvimento de aplicações LLM!
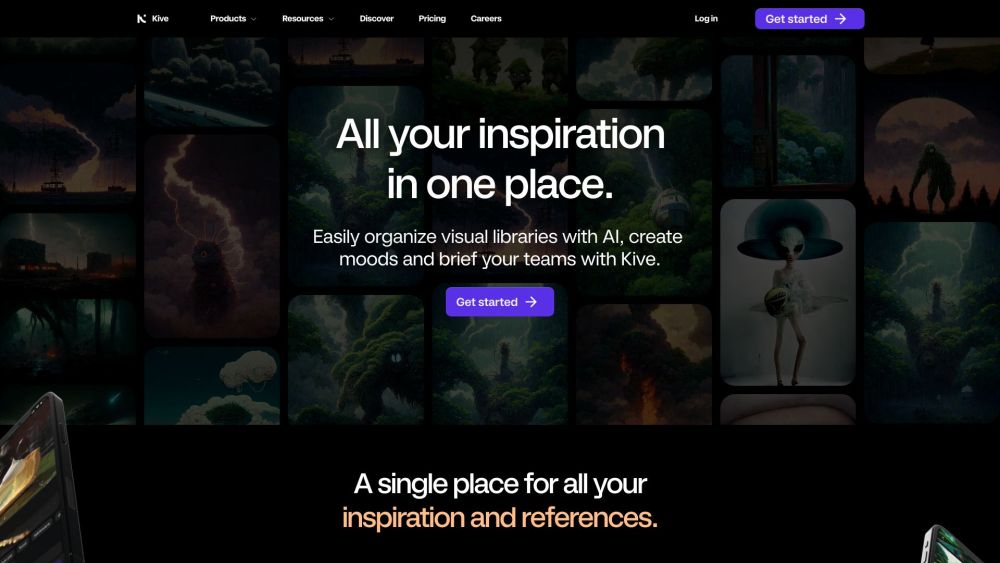
Kive é uma plataforma de IA inovadora projetada para gerenciar ativos criativos de forma integrada, inspirar a colaboração e aprimorar o processo criativo.
Find AI tools in YBX
