Reddit fecha parceria de $60 milhões com o Google para aprimorar ferramentas de inteligência artificial, segundo relatórios.
Most people like
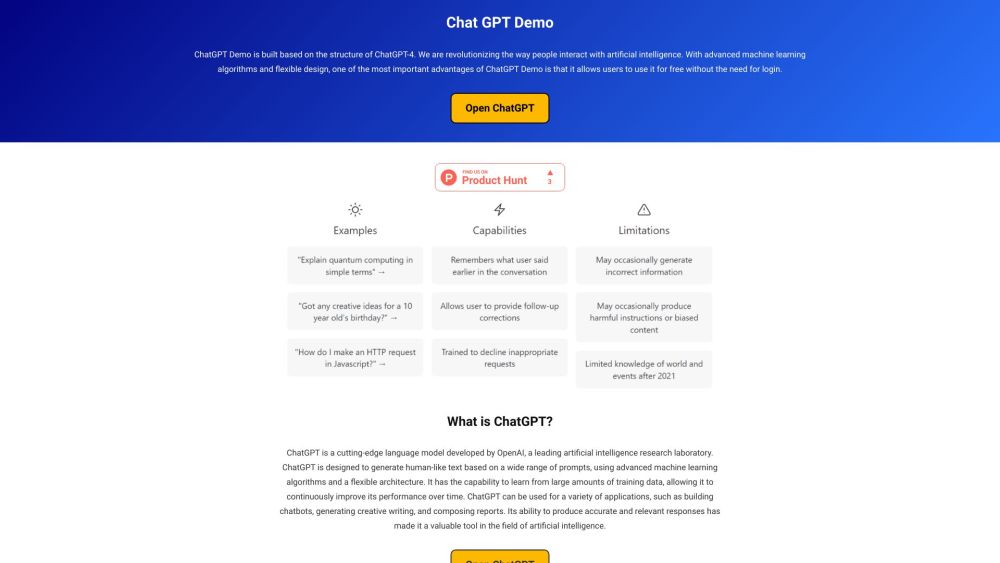
Descubra um chatbot de IA gratuito, impulsionado pelo Chat GPT-4, projetado para oferecer uma experiência do usuário envolvente e interativa.
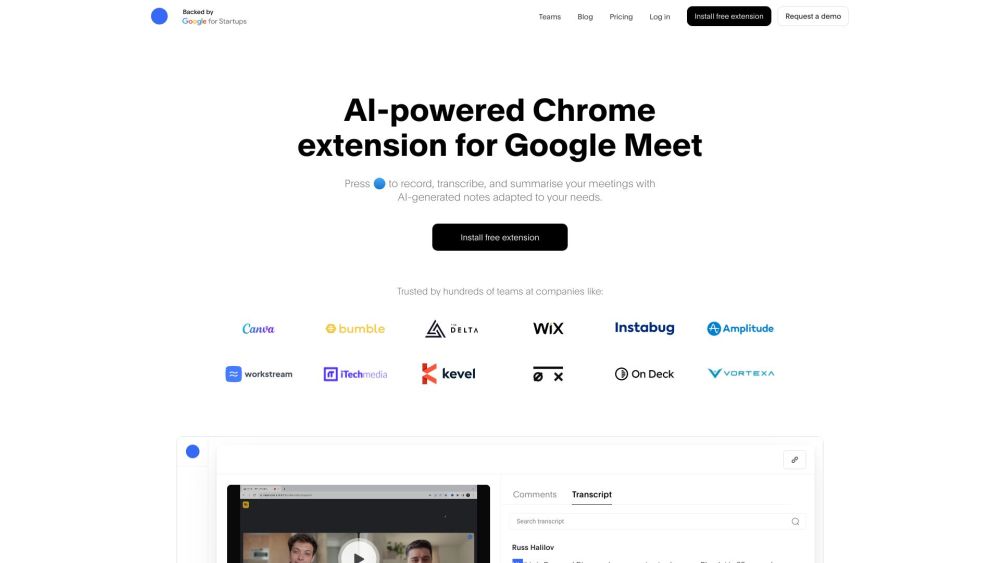
Apresentamos uma extensão do Chrome impulsionada por IA, projetada para anotações automáticas de reuniões. Transforme a forma como você captura e organiza suas discussões com esta ferramenta avançada, garantindo que você nunca perca um detalhe importante. Experimente uma produtividade aprimorada e otimize seu fluxo de trabalho com anotações fáceis, ao seu alcance.
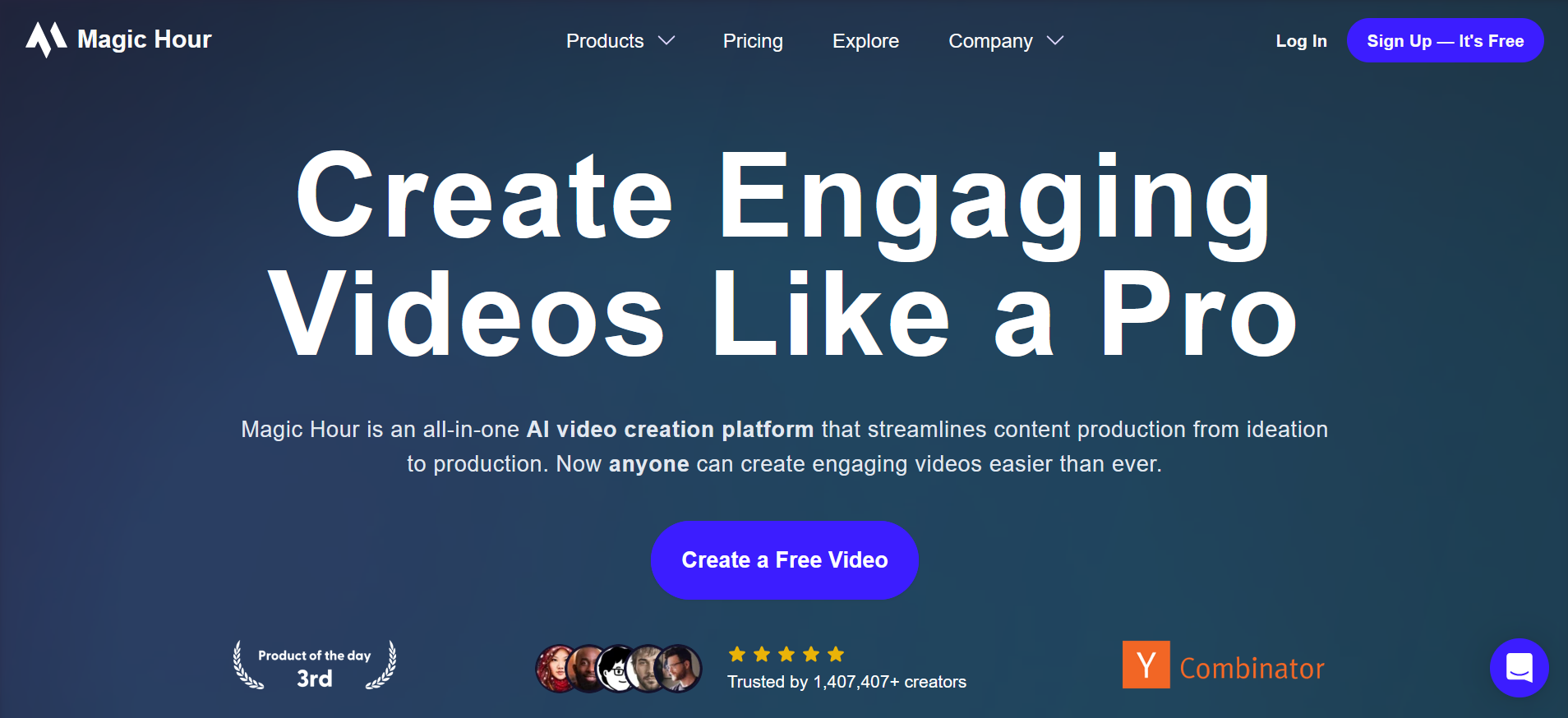
Magic Hour é uma plataforma de criação de vídeos com IA que simplifica a produção de conteúdo, desde a concepção até a finalização.
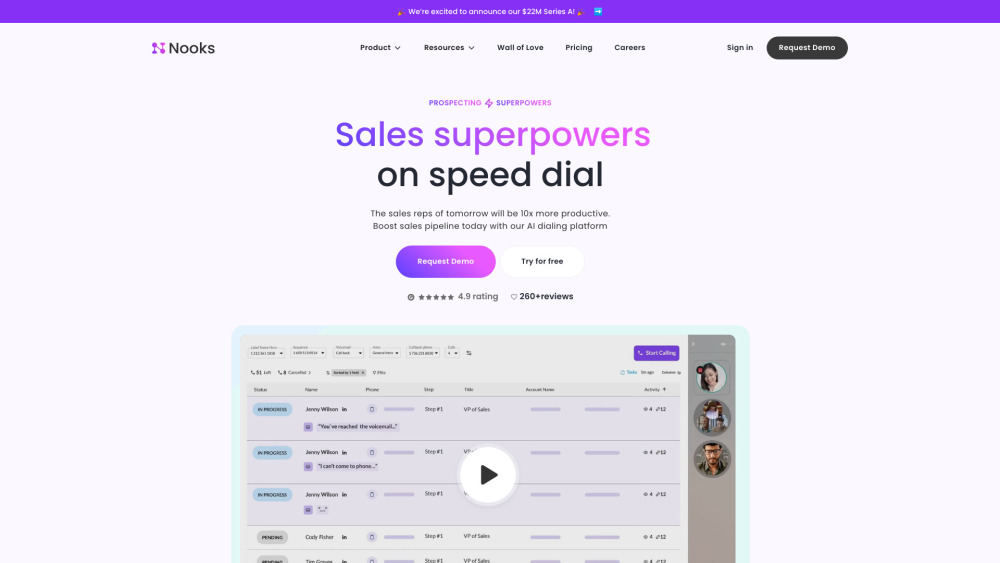
No ambiente de negócios acelerado de hoje, maximizar a produtividade de vendas é essencial para o sucesso. Uma plataforma de produtividade de vendas impulsionada por IA utiliza tecnologia avançada para otimizar processos de vendas, melhorar o desempenho da equipe e impulsionar o crescimento da receita. Ao automatizar tarefas repetitivas, fornecer insights valiosos e facilitar um melhor engajamento com os clientes, essa solução inovadora capacita as equipes de vendas a se concentrarem no que fazem de melhor—fechar negócios. Junte-se a nós enquanto exploramos como a integração da IA na sua estratégia de vendas pode transformar sua abordagem à produtividade e proporcionar resultados mensuráveis.
Find AI tools in YBX
Related Articles
Refresh Articles