Google DeepMind запускает "суперчеловеческую" ИИ-систему: революция в проверке фактов, снижение затрат и повышение точности.
Most people like
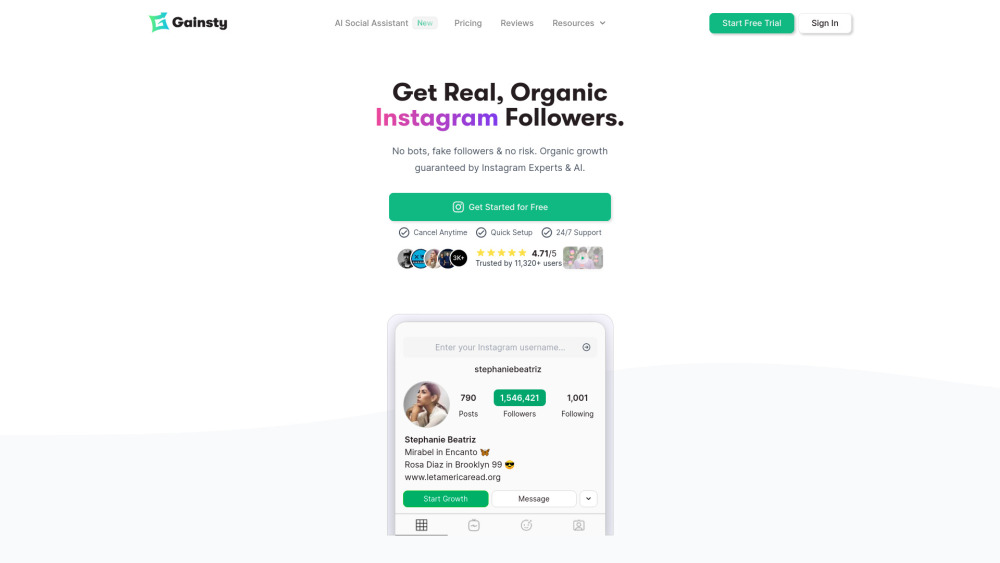
Разблокируйте рост органических подписчиков в Instagram с нашей платформой на базе ИИ. Наш инновационный инструмент, разработанный для улучшения вашего присутствия в социальных сетях, использует передовые алгоритмы для эффективного взаимодействия с вашей целевой аудиторией. Ощутите безупречный процесс привлечения настоящих подписчиков и органичного увеличения охвата вашего бренда. Присоединяйтесь к нам и измените свою стратегию в Instagram уже сегодня!
Представляем нашу платформу ИИ, созданную специально для написания, редактирования и исследований. Этот инновационный инструмент использует мощь искусственного интеллекта, чтобы улучшить ваши писательские навыки, упростить процесс редактирования и поддержать глубокое исследование. Будь вы студент, профессионал или креативный мыслитель, наша платформа ИИ призвана поднять ваш процесс создания контента на новый уровень. Узнайте, как наша технология может преобразовать ваши письменные проекты с точностью и эффективностью.
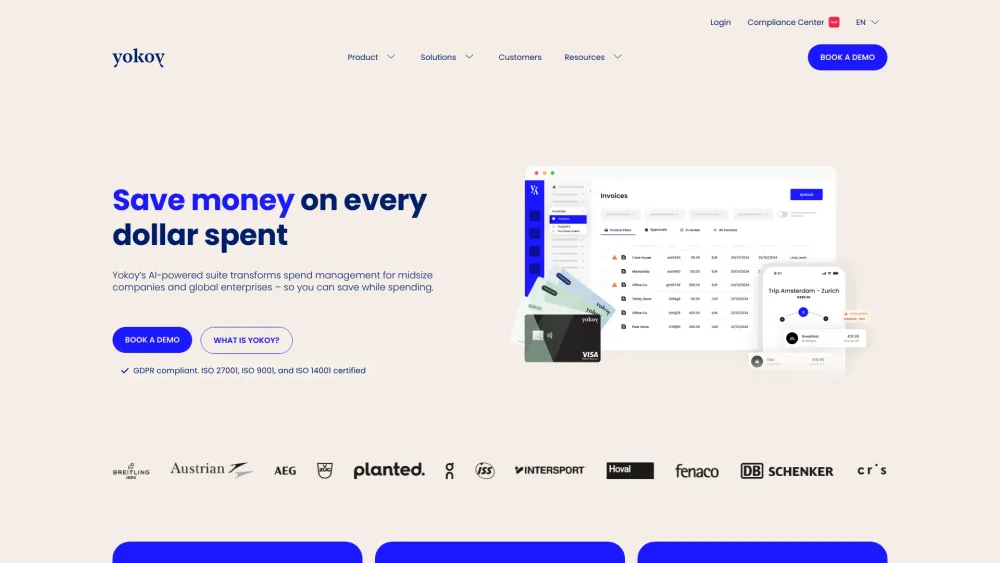
Откройте для себя возможности нашего набора решений на основе ИИ, созданного специально для эффективного управления расходами. Это инновационное решение использует передовые технологии для оптимизации бюджета, упрощения расходов и улучшения финансовой отчетности. С нашими инструментами на базе ИИ организации могут получать ценные аналитические данные, улучшать процесс принятия решений и добиваться значительных экономий. Преобразите свою финансовую стратегию сегодня с нашей комплексной платформой управления расходами.
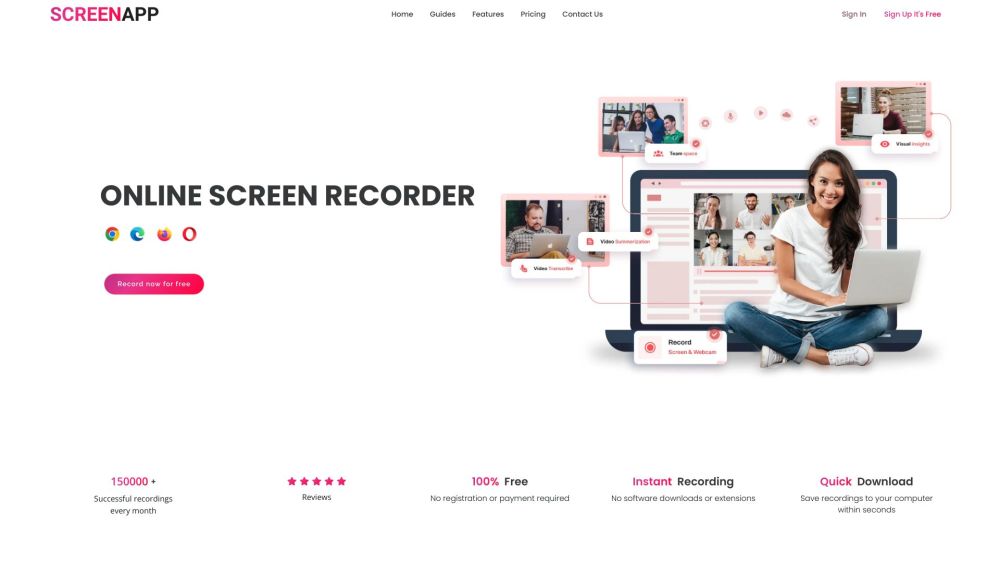
Представляем ScreenApp: бесплатный экранный рекордер с передовыми технологиями транскрипции на базе ИИ, предназначенный для простого захвата и обмена вашими идеями. Идеально подходит для повышения продуктивности и улучшения коммуникации, ScreenApp позволяет легко записывать и транскрибировать ваши действия на экране, гарантируя, что вы не упустите ни одной детали.
Find AI tools in YBX
Related Articles
Refresh Articles