Google 的創新技術賦予大型語言模型無限的語境理解能力
Most people like
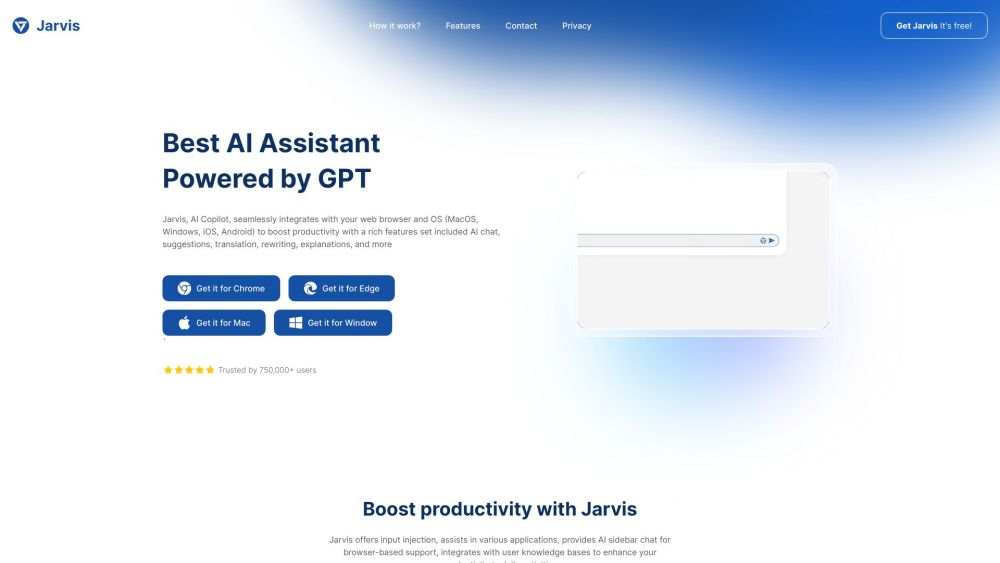
提升您的生產力,與 AI 助手同行
探索 AI 助手如何轉變您的工作流程,並最大化效率。這一強大工具簡化了任務,幫助您在更短的時間內實現更多,同時提升協作與創意。擁抱生產力的未來,今天就與 AI 助手共同釋放您的潛能!
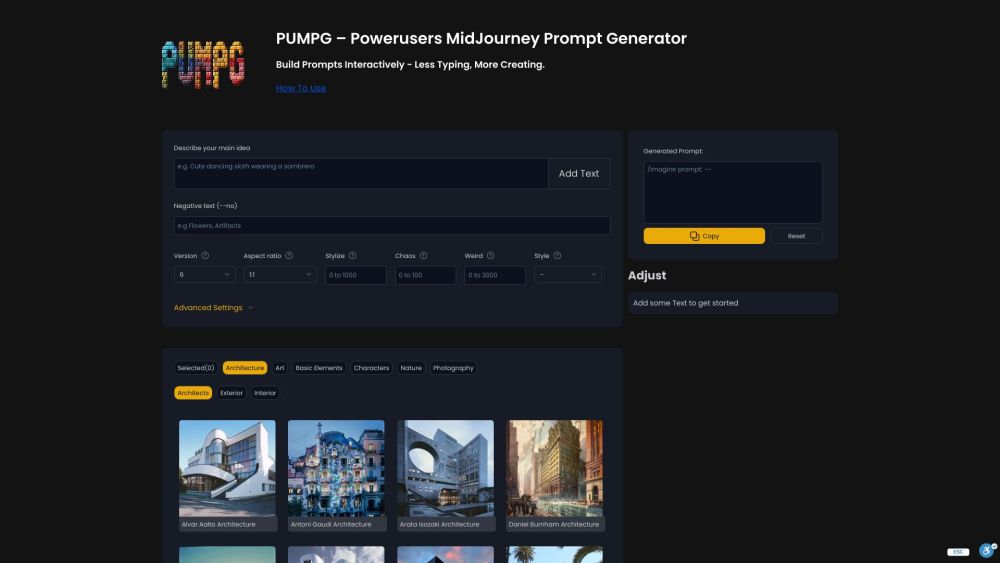
透過我們簡易的提示生成器,釋放創意的力量。無論您是作家、教師,還是僅僅想要激發新靈感,創作獨特的提示從未如此簡單。瞭解如何只需幾下點擊,就能提升您的寫作體驗,激發新的思考。立即投入,開始創建吸引人的提示吧!
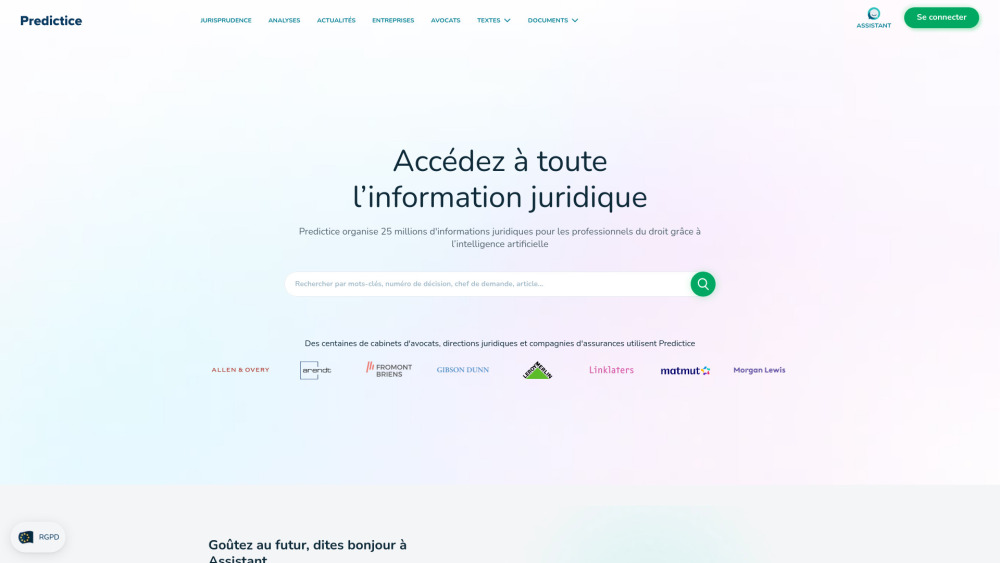
在當今快速變化的法律環境中,法律研究的效率至關重要。我們的平台徹底改變了法律專業人士搜尋和分析文件的方式,提供直觀的功能和先進的算法,以簡化過程。借助我們的高級工具,使用者可以輕鬆定位相關法律文件,深入獲取見解,並提升整體生產力。體驗一個新的法律研究時代,讓法律從業者能輕鬆做出明智的決策。
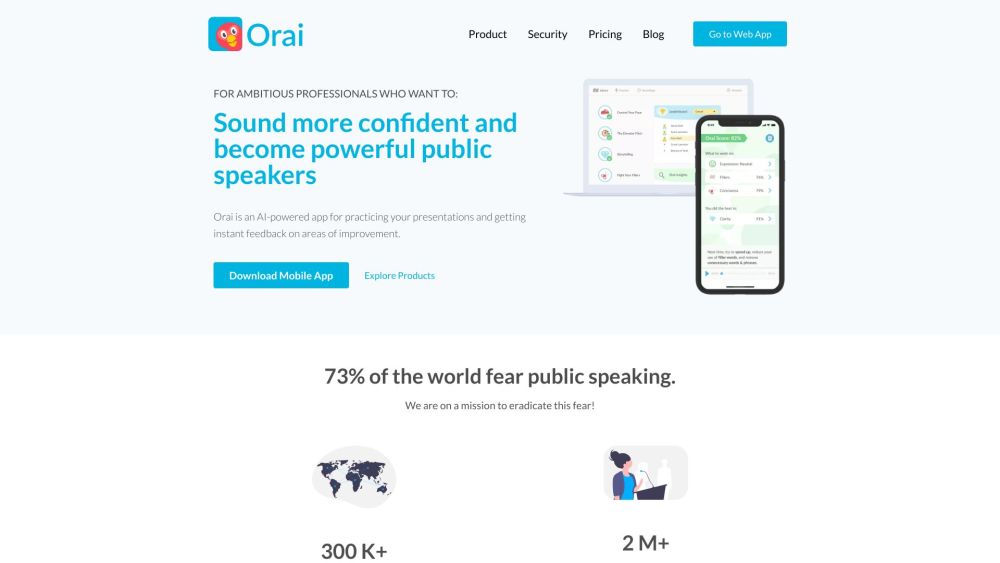
介紹一款創新的人工智慧應用程式,旨在提升您的演講技巧。這個先進的工具提供個性化的反饋和即時分析,使使用者能夠有效地練習和完善他們的演講。不論您是在準備工作面試、學術報告或公共演講活動,這款應用程式都是提升自信和改善表達的完美平台。今天就利用我們尖端的人工智慧技術,改變您的公共演講能力,追求卓越。
Find AI tools in YBX
Related Articles
Refresh Articles