NVIDIA的人工智慧團隊據報導在未經同意的情況下擷取了YouTube和Netflix的視頻內容。
Most people like
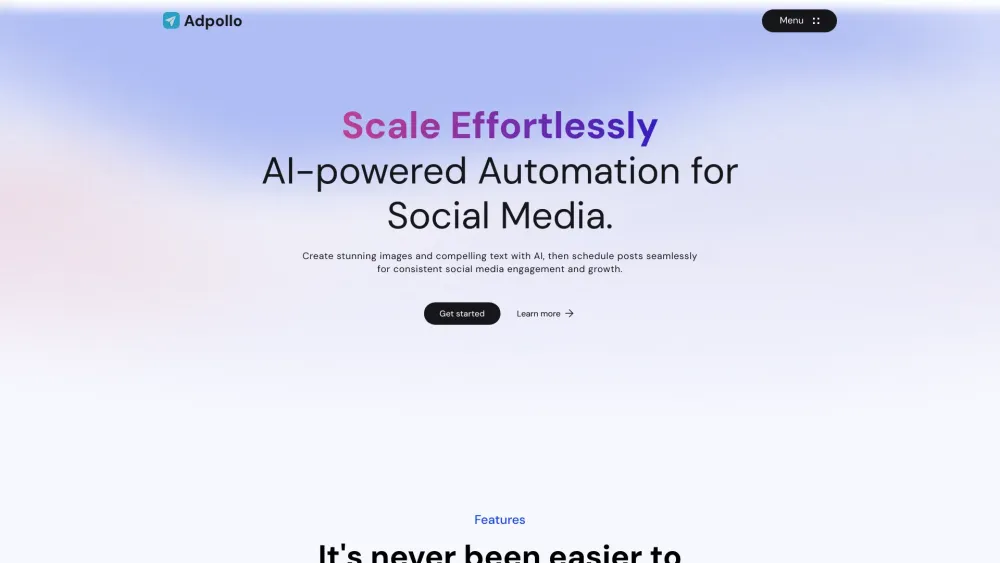
透過我們的AI驅動平台,輕鬆改變您的社交媒體存在,專為無縫內容生成與排程而設計。輕鬆創建與您的受眾共鳴的引人入勝的帖子,並優化您的社交媒體策略以達到最大影響。不論您是小型企業、網紅還是行銷專家,我們的工具使過程簡化,幫助您在社交媒體競爭中保持領先。

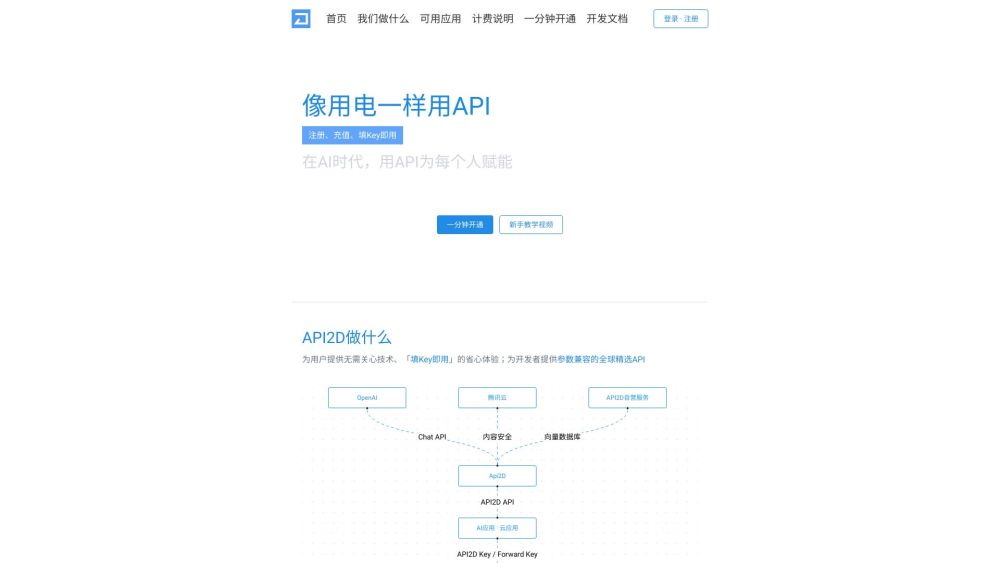
API2D 是一款強大的 OpenAI API,旨在無縫連接第三方應用程式,實現各種人工智慧任務,例如自然語言處理 (NLP)、機器學習 (ML)、對話生成和語言翻譯。這個多功能的工具增強了開發者和企業整合先進 AI 功能的能力。
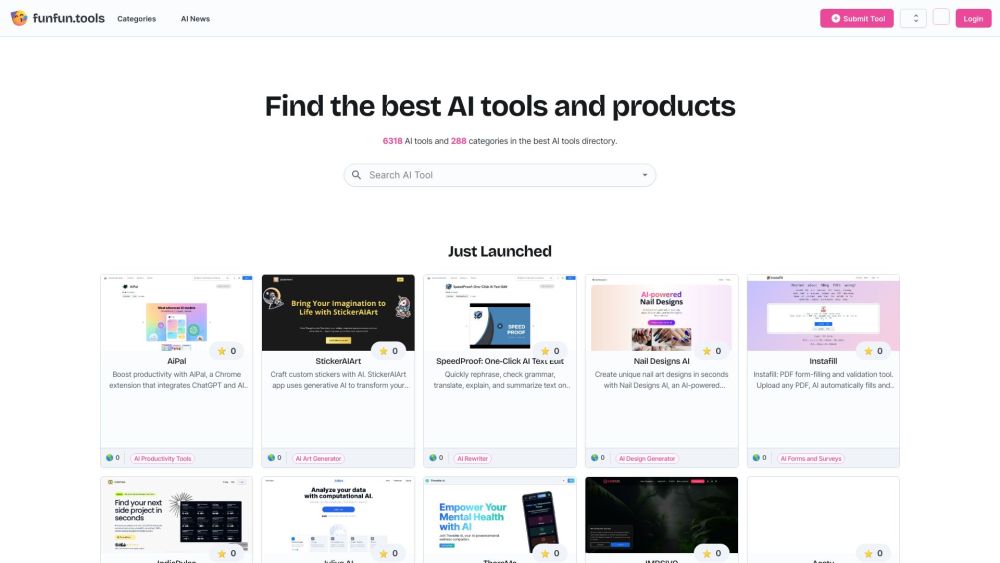
探索當前最佳的人工智慧工具!利用尖端技術釋放人工智慧的潛力,以提升您的專案。無論您是企業主、開發者還是愛好者,這份精心彙整的清單將指導您找到最有效的人工智慧解決方案,以簡化工作流程並提高生產力。立即深入探索,找到滿足您需求的完美工具!
Find AI tools in YBX
Related Articles
Refresh Articles