Slack 利用您的聊天數據來提升機器學習模型,以改善用戶體驗
Most people like
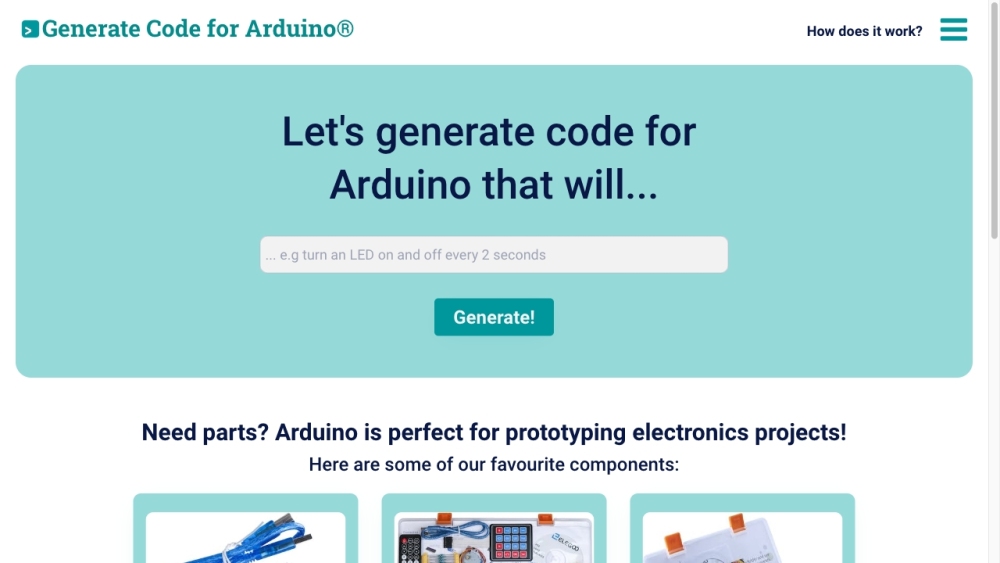
探索如何透過一個AI驅動的網站,以單擊一下生成Arduino代碼,來簡化您的項目開發過程。簡化的編碼過程讓各級創作者能輕鬆實現他們的創意。
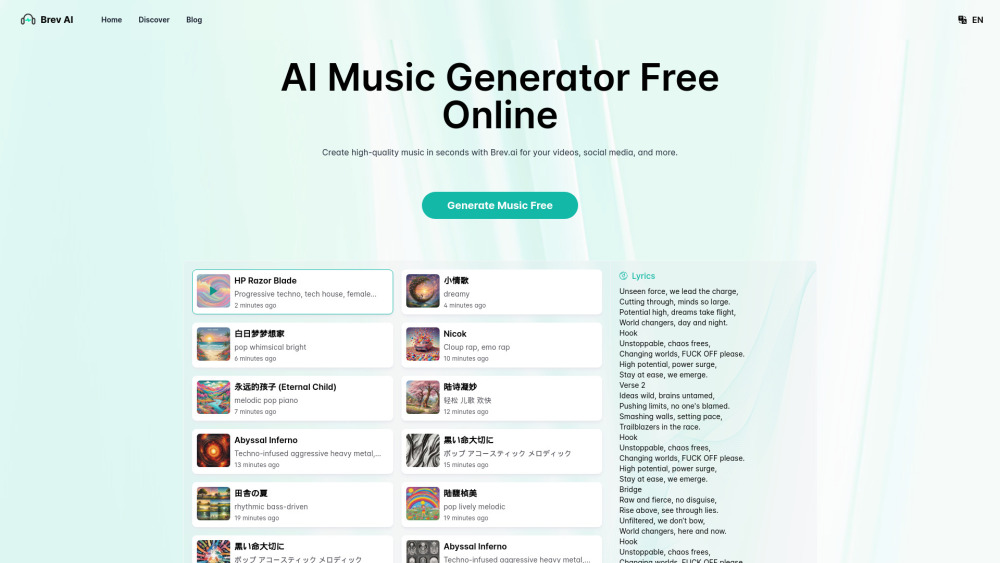
介紹AI音樂生成器:輕鬆創作高品質歌曲
探索AI音樂生成器的強大功能,這是您創作卓越歌曲的萬能解決方案。這項創新技術利用人工智慧來生成符合您風格和偏好的高品質音樂。無論您是經驗豐富的音樂家還是充滿熱情的愛好者,我們的AI音樂生成器都能讓您以前所未有的方式創作和完善歌曲。今天就釋放您的創意,提升您的音樂之旅!
Find AI tools in YBX
Related Articles

Refresh Articles