微軟推出VASA-1:一個使人類頭像生動起來的新AI框架,透過聲音和歌曲實現動態表現。
Most people like
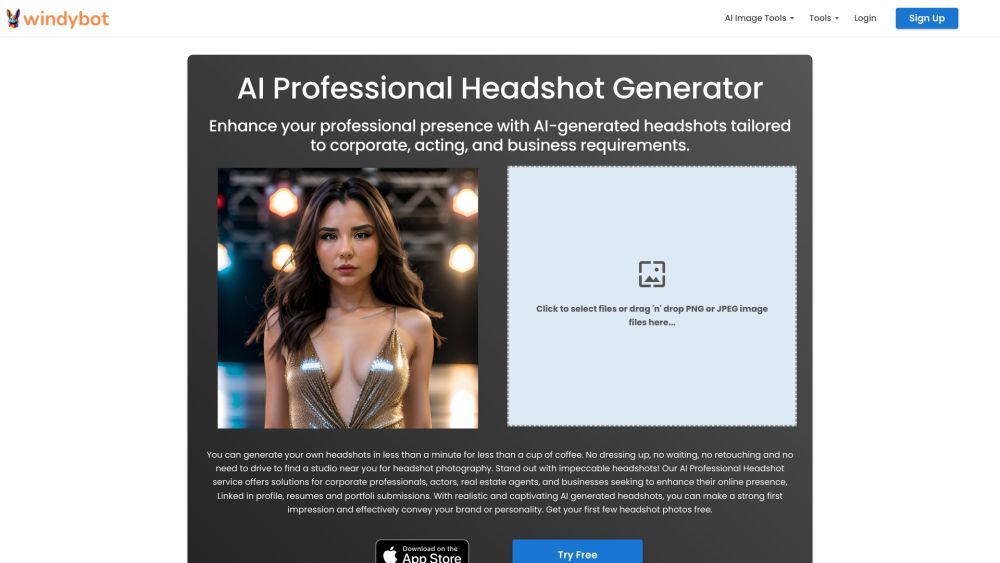
在當今的數位環境中,引人注目的視覺效果對於吸引注意力和傳達品牌信息至關重要。隨著科技的進步,專業影像增強的人工智慧工具已成為提升和完善攝影作品的強大資源。這些創新的解決方案使用戶能夠輕鬆調整光線、顏色和細節,確保每張圖片都能脫穎而出。無論您是攝影師、市場營銷人員,還是內容創作者,利用人工智慧進行影像增強都能顯著提升視覺內容的質量,更有效地吸引觀眾。


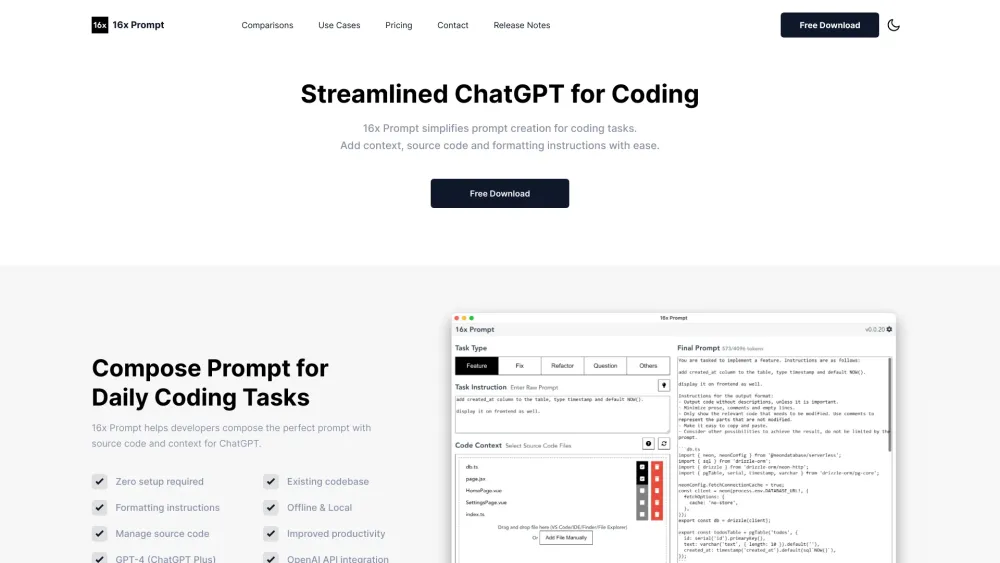
介紹一個專為程式編碼提示設計的精簡平台。這個使用者友好的工具提升您的編碼體驗,提供一個有序的空間來探索、創建和分享提示,讓您比以往更容易找到靈感並提高程式設計技能。加入我們的社群,今天就釋放您的編碼潛力!
Find AI tools in YBX
Related Articles
Refresh Articles