我們來自何處?探究數據及數據工具興起的背後原因
Most people like
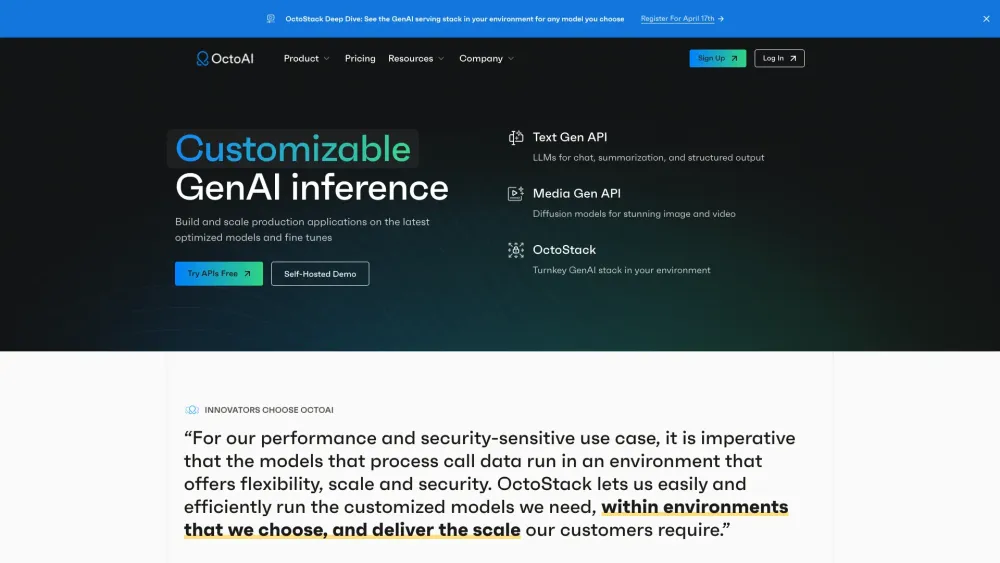
介紹一個專為生成式人工智能應用而設計的雲端平台。此創新解決方案利用雲端的力量來簡化流程、提升創意並推動人工智能開發的效率。探索我們的平台如何轉變您的項目,並在生成式人工智能領域釋放新可能性。
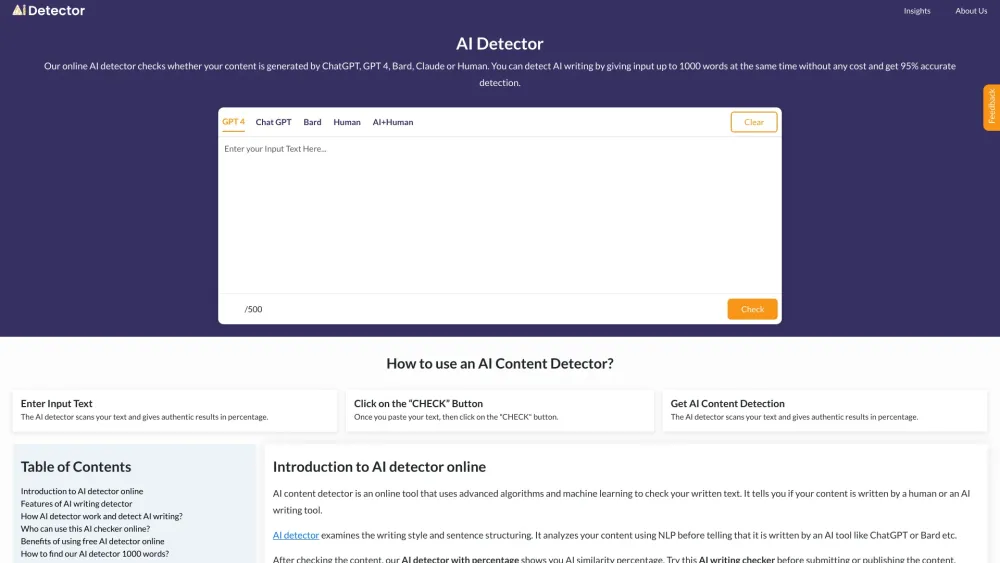
透過尖端算法釋放人工智能檢測的力量。探索這些高級技術如何提高識別人工智能生成內容的準確性和效率。藉助最先進的技術,企業和研究人員可以確保可靠的評估並改善決策過程。立即深入了解先進的人工智能檢測領域!
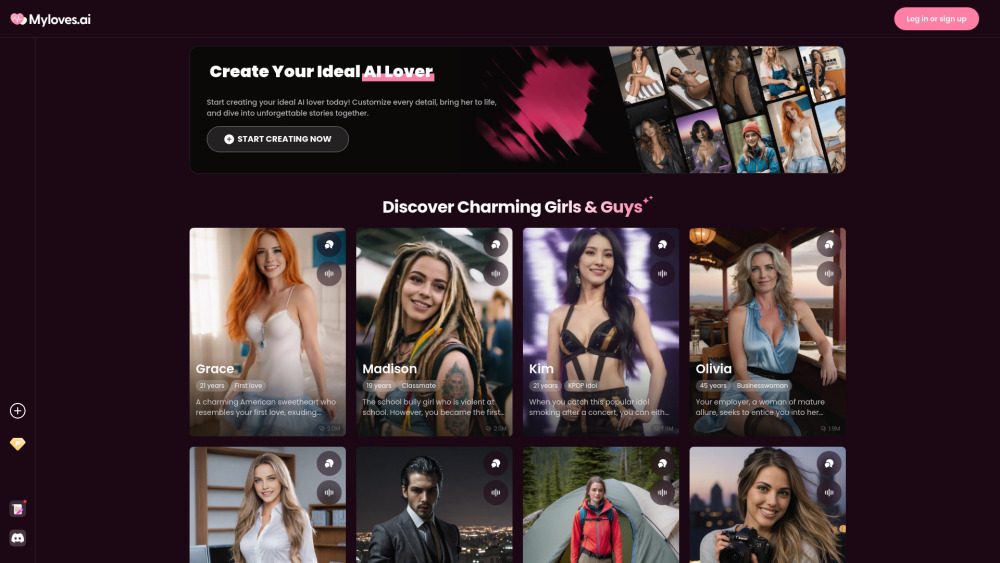
發掘個人化人工智慧伴侶的令人興奮潛力。通過我們的平台,您可以創建一位獨特的AI愛人或女友,充分展現您的喜好與渴望。無論您是在尋找陪伴還是更深層的情感聯繫,我們的自定義選項讓您能設計出完全符合您的理想虛擬伴侶。今天就來體驗未來的關係吧!

深入探索引人入勝的 NSFW AI 聊天與影像生成世界,這裡的先進人工智慧技術創造出動態且引人入勝的成人內容。這個革命性領域將創意與尖端演算法相融合,生產出獨特的文本與視覺,推動傳統媒體的邊界。瞭解 AI 如何透過提供個性化體驗和創新敘事,改變成人娛樂,同時應對 NSFW 內容的複雜性與倫理考量。與我們一起探索這個技術與藝術交匯的迷人領域。
Find AI tools in YBX
Related Articles

Refresh Articles