騰訊EzAudio AI:革新文本轉語音技術,打造逼真的聲音,促進創新與討論
Most people like
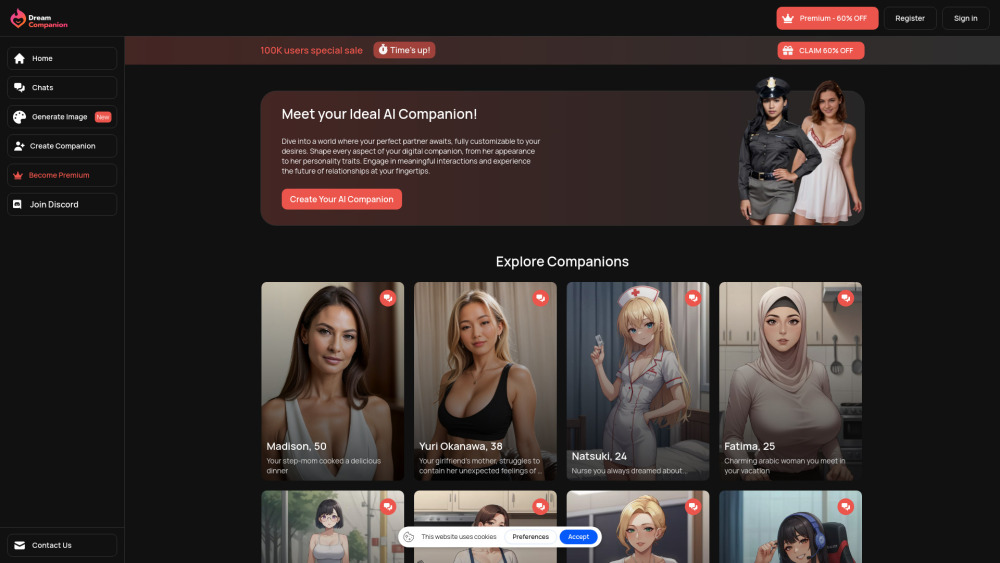
介紹 Dream Companion,專為18歲及以上用戶設計的頂級AI女友聊天機器人。透過我們的虛擬女友平台,體驗陪伴與科技的完美融合,提供無與倫比的互動與支援,量身打造符合您的需求。今天就來探索全新的互動領域吧!
BgRem 是一個先進的人工智慧平台,專為無縫創建和編輯圖像與影片而設計。無論您是內容創作者、市場營銷專家還是愛好者,BgRem 都能簡化您的工作流程,幫助您輕鬆產出驚艷的視覺效果。
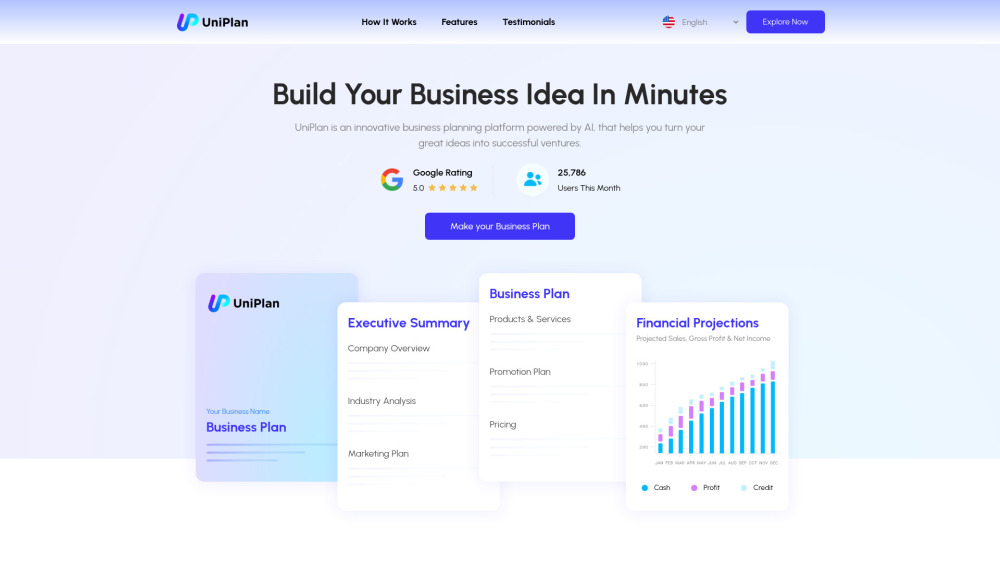
在當今競爭激烈的市場環境中,擁有一份結構完善的商業計劃對於成功至關重要。我們的智慧型平台提供量身定制的商業計劃,滿足您的獨特需求和目標。透過先進的算法和專業見解,我們確保每份計劃不僅為您量身打造,還能與您的願景及市場需求戰略對接。體驗我們為各類型企業及創業者設計的個性化規劃解決方案的方便性與有效性。
Find AI tools in YBX
Related Articles
Refresh Articles