克服挑战:企业为何难以在2023年纽约人工智能峰会实现人工智能落地
Most people like
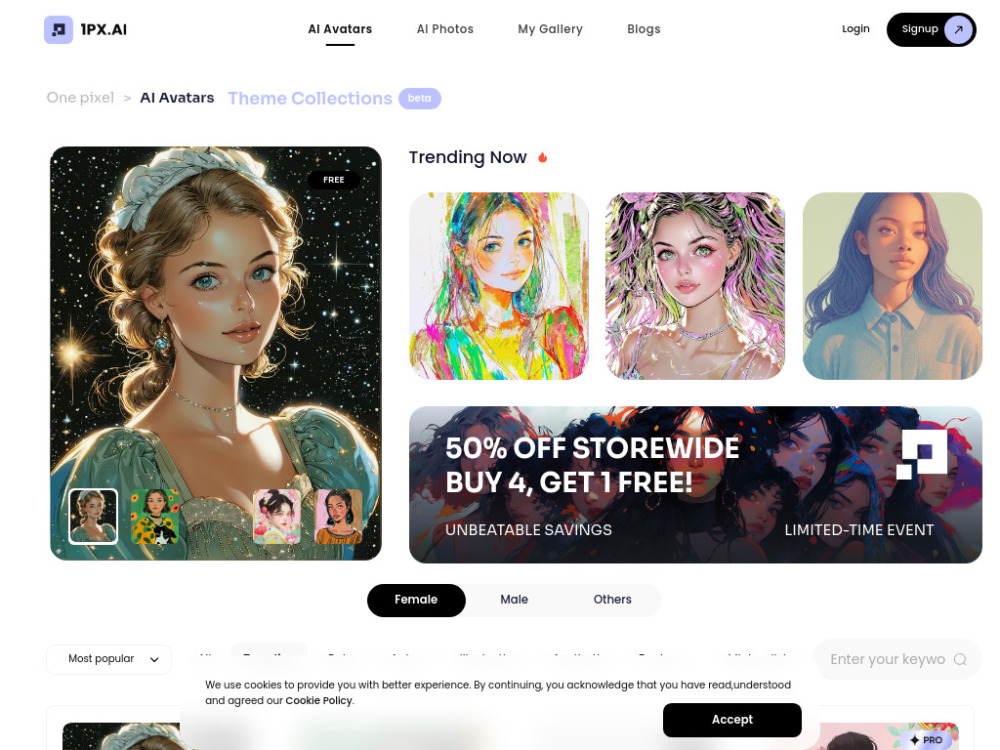
在数字艺术和创造性表达迅速发展的今天,AI肖像生成器正变得越来越受欢迎。这些智能工具利用先进的算法和深度学习技术,能够生成惊艳的肖像,无论是现实主义风格还是超现实主义作品。从艺术家到企业,越来越多的人们正在利用这些工具来实现创意灵感和提升视觉内容的质量。本文将深入探讨AI肖像生成器的工作原理、应用场景以及它们如何革新传统艺术创作的方式。
发现强大的免费AI文本分析工具,帮助您深入理解和解析文本内容。我们的工具提供智能数据处理,以及准确的文本解读,让您提升写作效率和数据分析能力。立即体验,提高您的文本分析能力,释放创意潜力!
Find AI tools in YBX
Related Articles
Refresh Articles