苹果、英伟达和Anthropic被指未经同意使用YouTube转录文本进行AI模型训练
Most people like
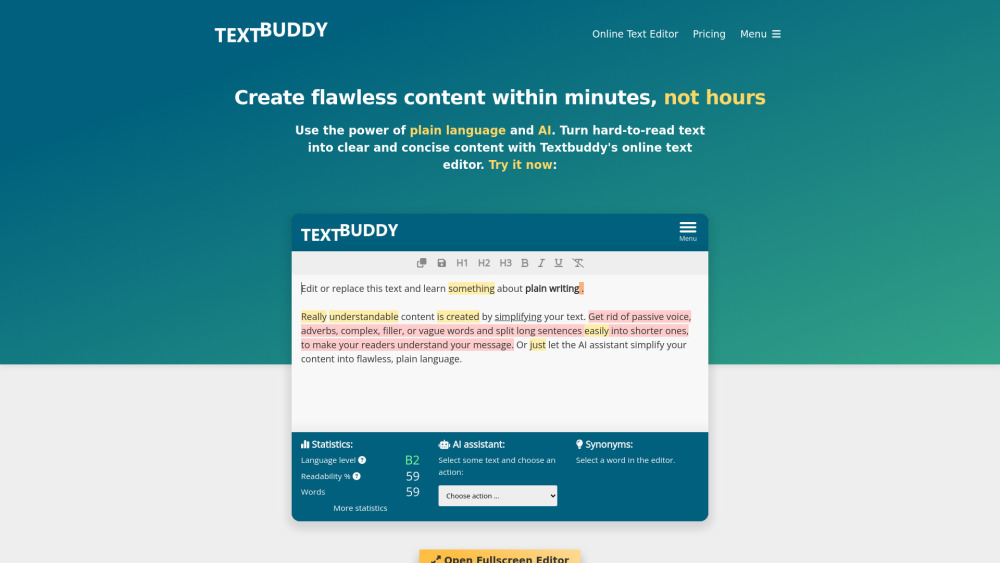
AI文本编辑器:提升清晰简洁写作的智能工具
在信息泛滥的时代,清晰和简洁的表达愈发重要。我们的AI文本编辑器专为帮助用户提升写作质量而设计,不论是撰写学术论文、商业文档,还是创意文章。利用先进的算法,它将纠正语法错误、优化句子结构,并提供个性化建议,让您的文本更加专业和易于理解。立即体验,提升您的写作能力,确保您的信息传达快速而有效。
Find AI tools in YBX
Related Articles
Refresh Articles