Meta推出LLM编译器模型:提升AI编程技能,实现高效代码优化
Most people like

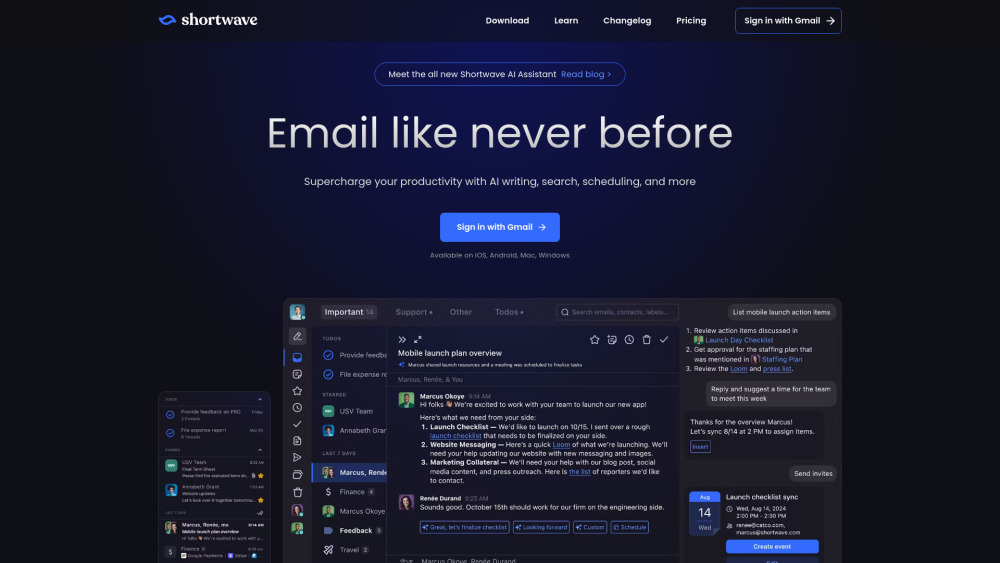
基于人工智能的邮件管理和生产力提升工具,旨在优化您的工作流程,提高工作效率。通过智能算法,这些工具能够自动分类、优先处理邮件,并提供智能提醒,让您专注于最重要的任务。
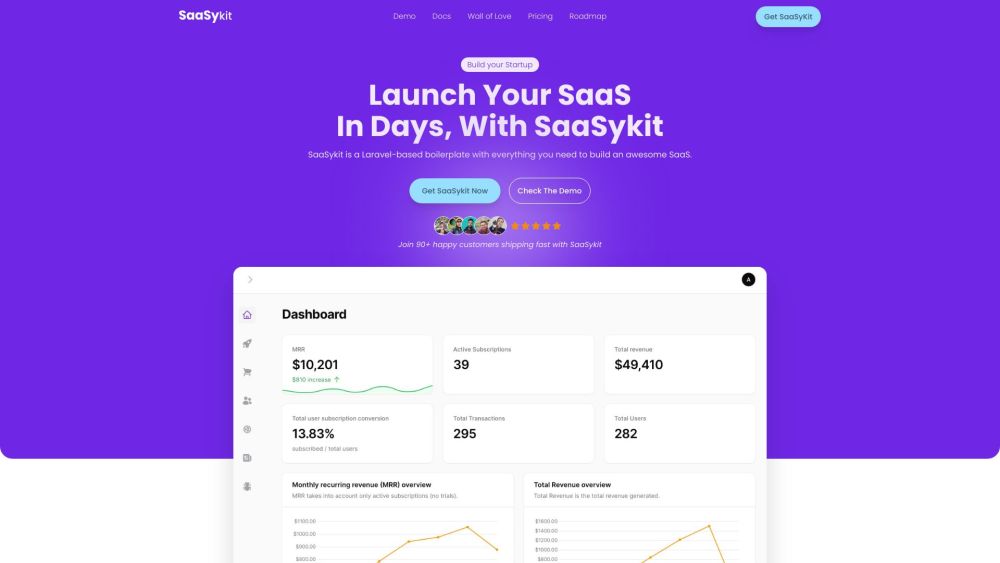
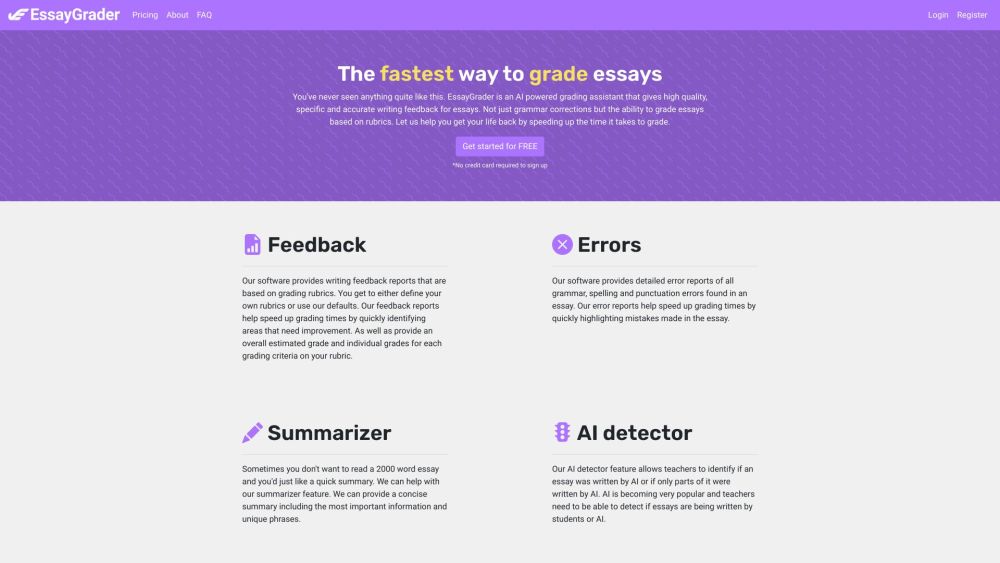
Find AI tools in YBX
Related Articles
Refresh Articles