Stable Audio 开放:Stable AI开源音频生成模型为音频创作带来了新选择
Most people like
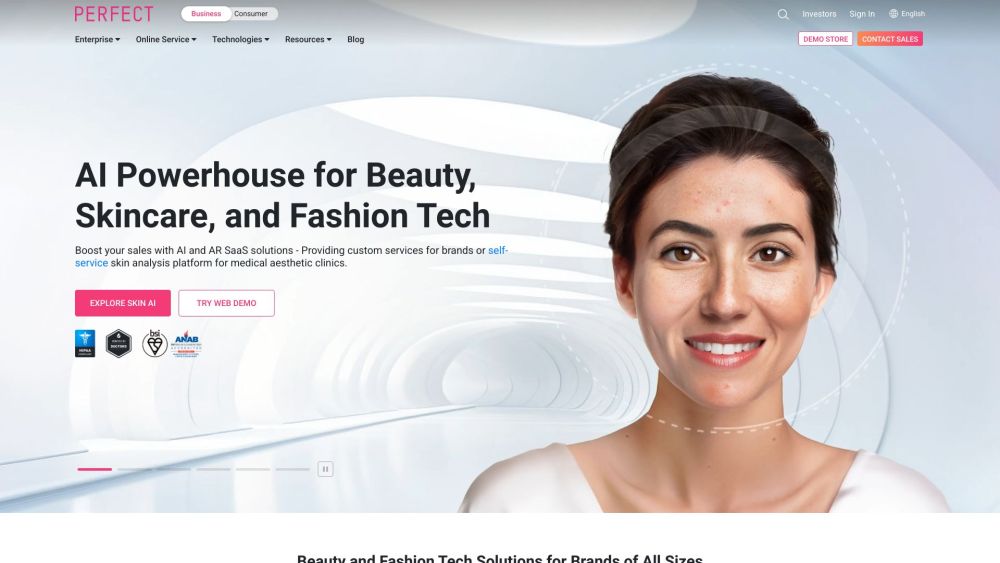
美容、时尚与护肤行业正迅速融入AI和AR技术,开创全新体验。这些创新的解决方案不仅提升了消费者的购买决策,还改善了整体服务。这篇文章将探讨AI和AR如何重塑美容和时尚领域,提升护肤体验,并推动行业走向未来。

Find AI tools in YBX
Related Articles
Refresh Articles