亚马逊加强Alexa人工智能,实现更自然的对话体验
Most people like
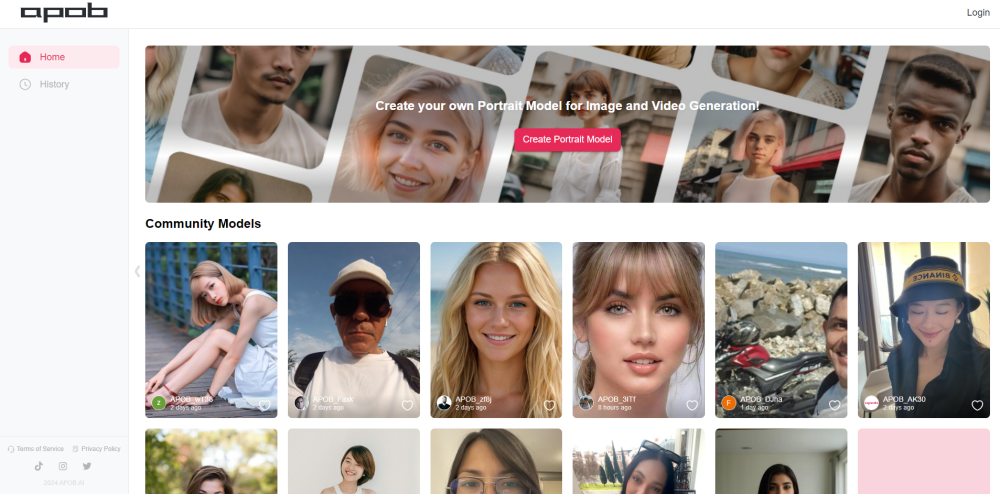
探索AI虚拟形象创建工具,这是一款创新的技术,旨在帮助用户轻松设计和生成个性化的虚拟形象。无论是用于社交媒体、游戏还是企业展示,AI虚拟形象创建工具都能提供无限的创意可能性。通过简单的界面和强大的功能,用户可以根据自己的需求,定制独特的形象,展现个性和风格。无论您是艺术家、企业主还是普通用户,这款工具都将成为您展现自我的理想助手。

Find AI tools in YBX
Related Articles
Refresh Articles