اكتشف قوة بيانات Google’s DataGemma AI: سحرك النهائي في الإحصاءات
Most people like
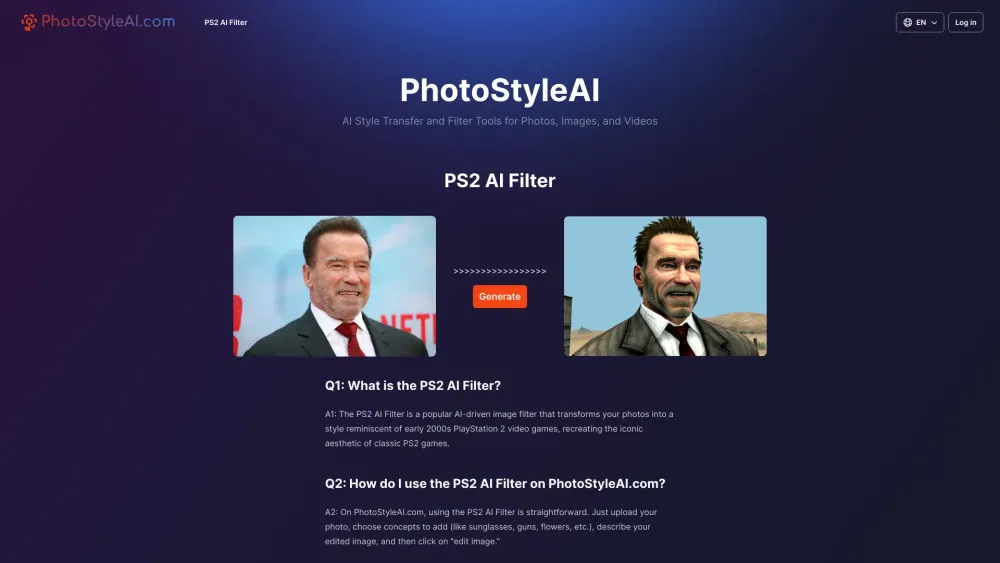
عزز صورك وم-images بسهولة باستخدام أدوات تحويل الأنماط والفلاتر المتقدمة المعتمدة على الذكاء الاصطناعي. حول مرئياتك بتقنية مبتكرة تُحيي الإبداع.
اكتشف فوائد دروس الرياضيات المعززة بالذكاء الاصطناعي، وهو نهج مبتكر مصمم لتعزيز التعلم والفهم في مادة الرياضيات. من خلال الاستفادة من التكنولوجيا المتقدمة، تقدم هذه الأنظمة الذكية دعمًا شخصيًا يتناسب مع أساليب وسرعات التعلم الفردية. سواء كنت تواجه صعوبة في الجبر أو الهندسة أو حساب التفاضل والتكامل المتقدم، يمكن لدروس الرياضيات المعززة بالذكاء الاصطناعي تحويل تجربتك التعليمية، مما يجعلها أكثر كفاءة وفعالية. احتضن مستقبل التعلم مع الحلول المدفوعة بالذكاء الاصطناعي لتحسين مهاراتك في الرياضيات!
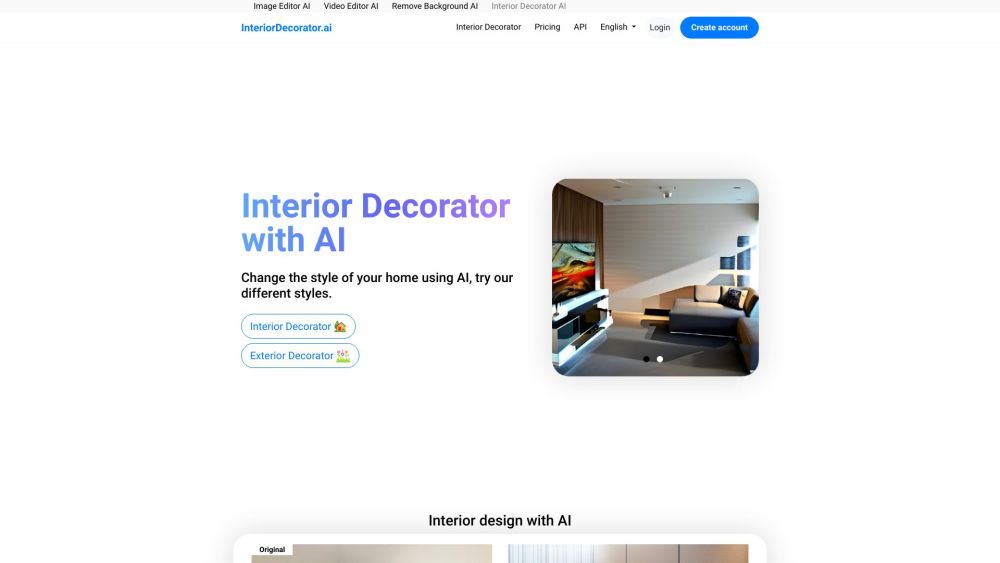
مرحبًا بكم في InteriorDecorator.ai، منصة الذكاء الاصطناعي المبتكرة التي تحول تصميم الديكور الداخلي من خلال توليد أفكار مخصصة لبيوتكم. من خلال استخدام خوارزميات الذكاء الاصطناعي المتقدمة، نقدم لكم اقتراحات ديكور فريدة مصممة لرفع مستوى مساحات المعيشة الخاصة بكم. استكشفوا مستقبل تصميم المنازل معنا اليوم!
في سوق العمل التنافسي اليوم، يعتبر التميز في المقابلات أمراً حيوياً للحصول على الوظيفة التي تحلم بها. تعرف على مساعد المقابلات المدعوم بالذكاء الاصطناعي—أداة ثورية مصممة لتعزيز مهاراتك في المقابلات وزيادة ثقتك بنفسك. من خلال التدريب المخصص، والتعليقات الفورية، وأسئلة التدريب المصممة حسب احتياجاتك، تساعدك هذه الحلول المبتكرة على الأداء بأفضل ما لديك. اكتشف كيف يمكن لهذه التقنية تحويل استعدادك للمقابلات وتمهيد الطريق نحو النجاح المهني.
Find AI tools in YBX
