زايبرا تطلق زيدا: مجموعة بيانات لنمذجة اللغة بحجم 1.3 تيرابايت تدعي أنها تتفوق على بايل وC4 وarXiv.
Most people like
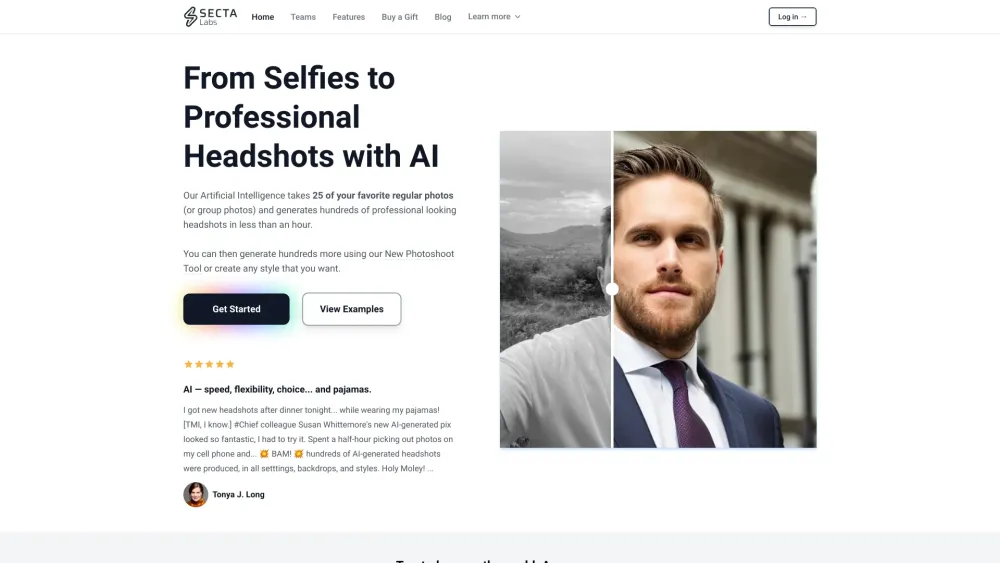
في عالم اليوم الرقمي، يُعَدُّ الانطباع الأول القوي أمرًا حاسمًا. تُعَزِّز الصور الشخصية المهنية المُنتَجة بواسطة الذكاء الاصطناعي وجودك على الإنترنت، كما تُعَبِّر عن احترافك وقابليتك للتواصل. باستخدام تكنولوجيا الذكاء الاصطناعي المتقدمة، تُصنَع هذه الصور لتلبية الأسلوب الفريد واحتياجات العلامات التجارية للأفراد والشركات على حد سواء. اكتشف كيف يمكن أن تُحَوِّلَ اعتماد الصور المُنتَجة بالذكاء الاصطناعي علامتك الشخصية والمهنية، مما يُميزك في بيئة تنافسية.
رفع تجربتك مع ChatGPT باستخدام Prompt Genie، الأداة المدعومة بالذكاء الاصطناعي المصممة لتعزيز مطالباتك وتقديم نتائج استثنائية. سواء كنت تبحث عن تحسين أسئلتك أو توليد ردود أكثر إبداعًا، يمكن لـ Prompt Genie مساعدتك في استكشاف الإمكانيات الكاملة لـ ChatGPT لتحقيق أفضل أداء.
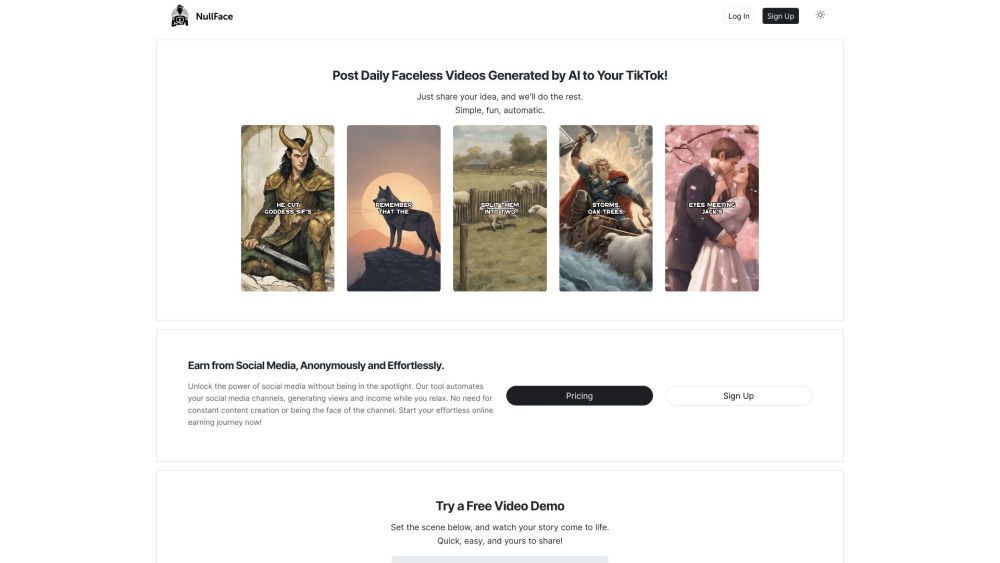
اكتشف منصتنا المدعومة بالذكاء الاصطناعي التي تخلق بيسر مقاطع فيديو جذابة بلا وجوه لتيك توك كل يوم. إنها وسيلة بسيطة وممتعة لتعزيز محتواك!
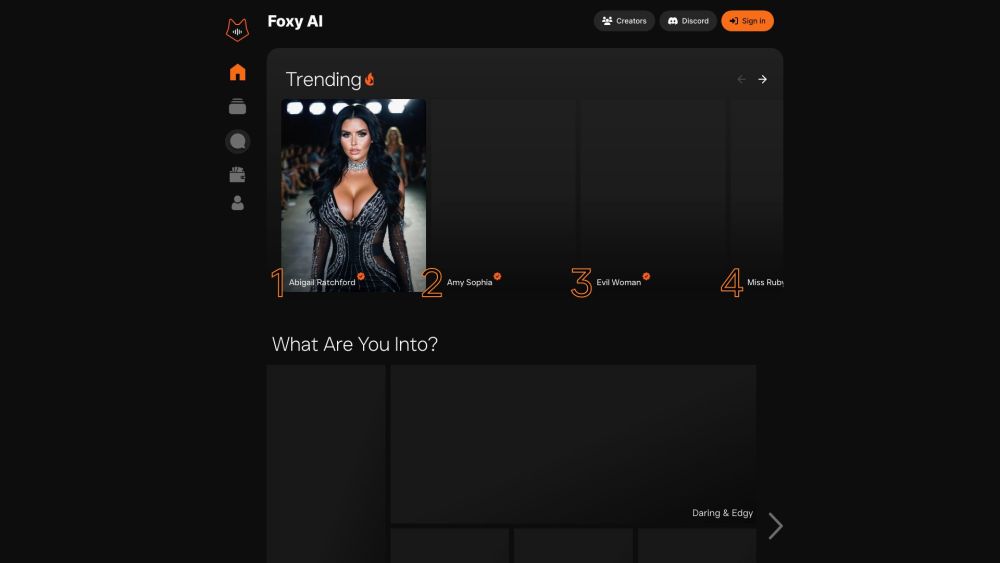
نقدم لكم المنصة الرائدة في مجال الذكاء الاصطناعي للمبدعين، المصممة لتمكين المبتكرين وتعزيز العمليات الإبداعية. بفضل أدواتنا ومواردنا القوية، أطلق خيالك وحوّل أفكارك إلى واقع. انضم إلى مجتمع من المبدعين الرائدين الذين يقومون بثورة في مجالاتهم باستخدام تكنولوجيا الذكاء الاصطناعي المتقدمة.
Find AI tools in YBX
Related Articles
Refresh Articles