ستابل أوديو أوبن: خيار جديد لإنشاء الصوت مع نموذج ستابل إيه آي المفتوح لتوليد الصوت.
Most people like
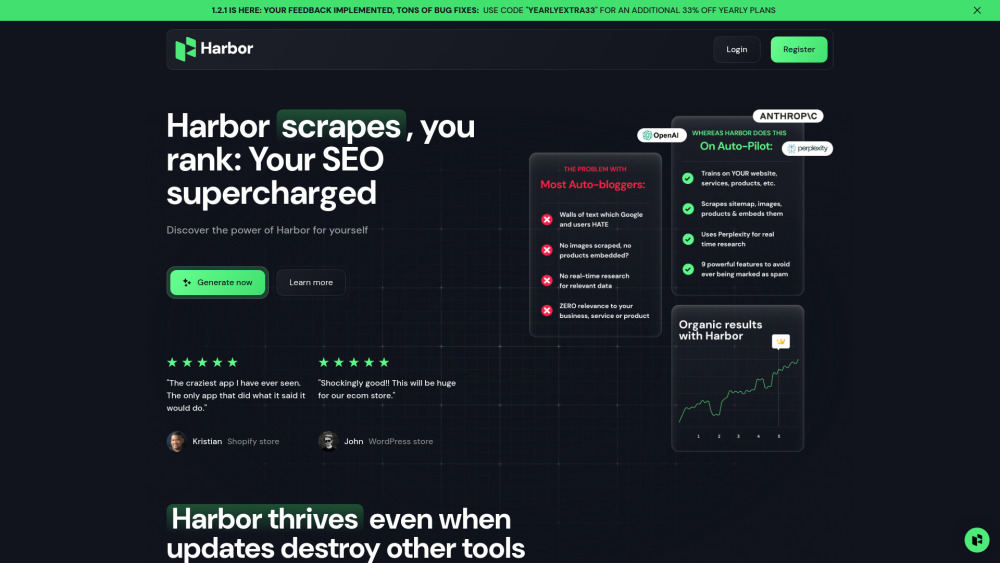
نقدم أداة قوية لتحسين محركات البحث مصممة لإنشاء مقالات ومنشورات مدونة محسّنة بكل سهولة. عزز استراتيجيتك للمحتوى وزيِّن حركة المرور العضوية من خلال استخدام منصتنا سهلة الاستخدام. سواء كنت مسوقًا محترفًا أو مبتدئًا، فإن أداتنا تُبسِّط عملية الكتابة، مما يضمن تصدُّر محتواك في نتائج محركات البحث مع جذب جمهورك بشكل فعَّال. افتح أمامك آفاقًا جديدة لزيادة الرؤية والتفاعل من خلال حلنا المبتكر.
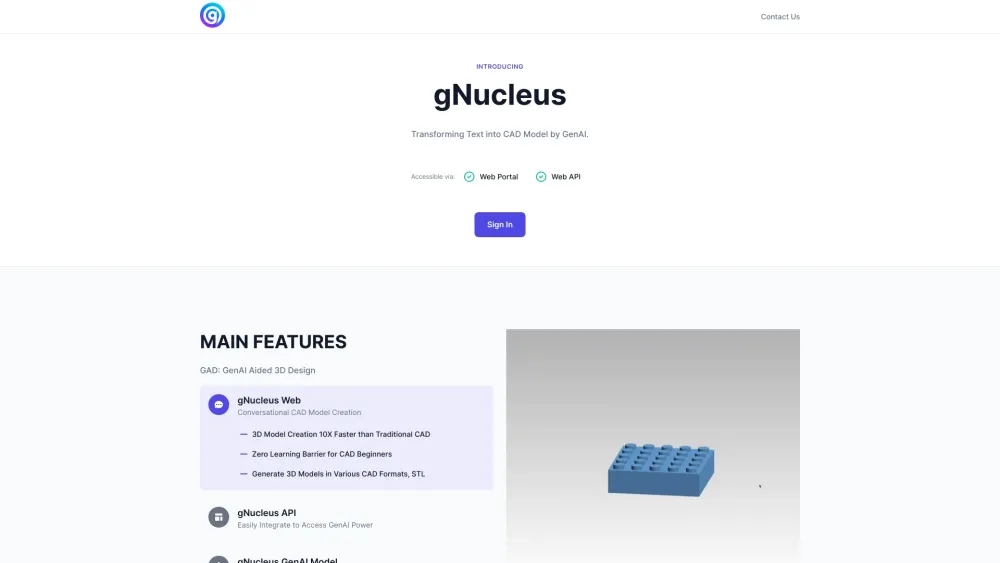
حوّل وصفك النصي إلى نماذج CAD ثلاثية الأبعاد مذهلة بسهولة. سواء كنت مصممًا أو مهندسًا أو هواة، فإن الحل المبتكر لدينا يتيح لك إنشاء نماذج ثلاثية الأبعاد معقدة مباشرة من مدخلاتك المكتوبة. اختبر مستقبل التصميم مع التحويل السلس من النص إلى CAD ثلاثي الأبعاد، مما يجعل أفكارك الإبداعية تنبض بالحياة بكلمات قليلة فقط.
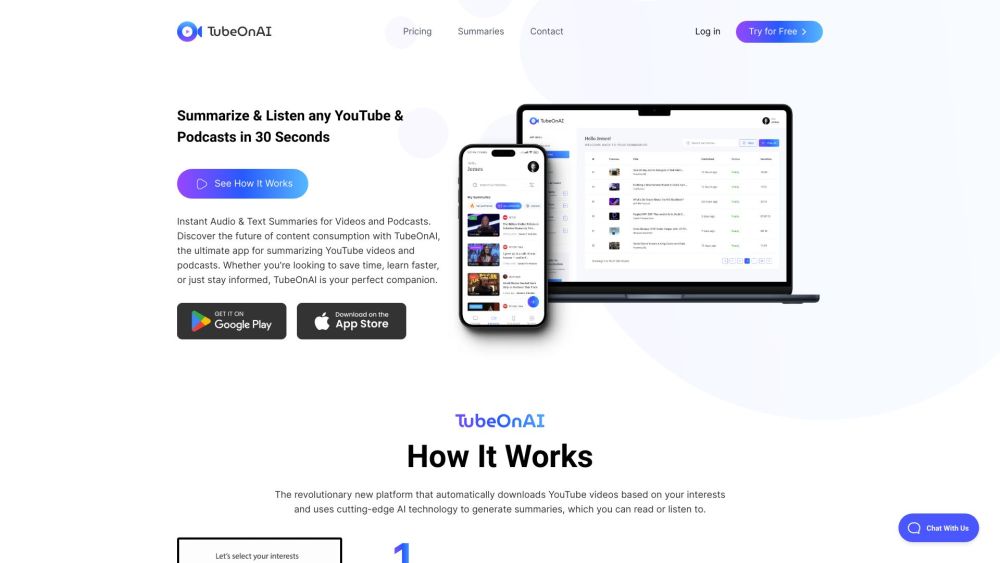
افتحوا آفاق القوة الملهمة للملخصات المدعومة بالذكاء الاصطناعي لتسهيل استهلاك الفيديو. اكتشفوا كيف تعزز هذه الأدوات المبتكرة تجربتكم في المشاهدة، مما يمكنكم من فهم الأفكار الرئيسية بسرعة وتوفير الوقت. احتضنوا الكفاءة مع ملخصات الفيديو المدعومة بالذكاء الاصطناعي اليوم!
Find AI tools in YBX
Related Articles
Refresh Articles