أعلنت Assembly AI عن نموذج Universal-1 الذي يتميز بتقليل نسبة الهلاوس بنسبة 30% مقارنة بنموذج Whisper.
Most people like

تفوّق في دراستك وامتياز في الواجبات بسهولة. اكتشف استراتيجيات فعالة للدراسة بذكاء، وليس بجهد زائد، لتحقيق النجاح الأكاديمي بلا عناء.
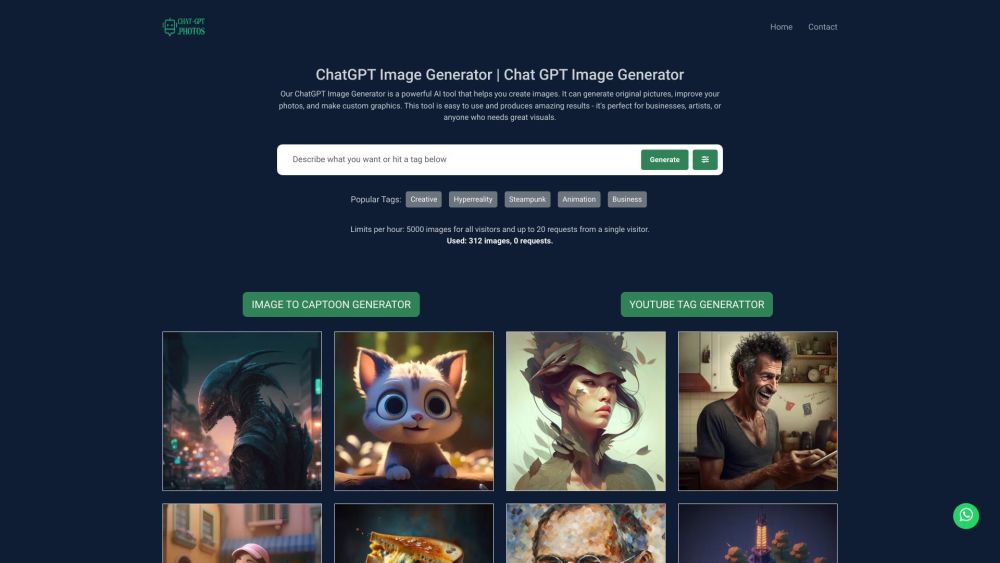
أطلق إبداعك مع مولد الصور ChatGPT! استكشف إمكانيات لا حصر لها وحوّل أفكارك إلى صور مذهلة باستخدام أداتنا القوية. سواء كنت فنانًا، مصممًا، أو مجرد شخص يتطلع للإبداع، يمكن لمولد الصور ChatGPT أن يحقق رؤاك كما لم يحدث من قبل!
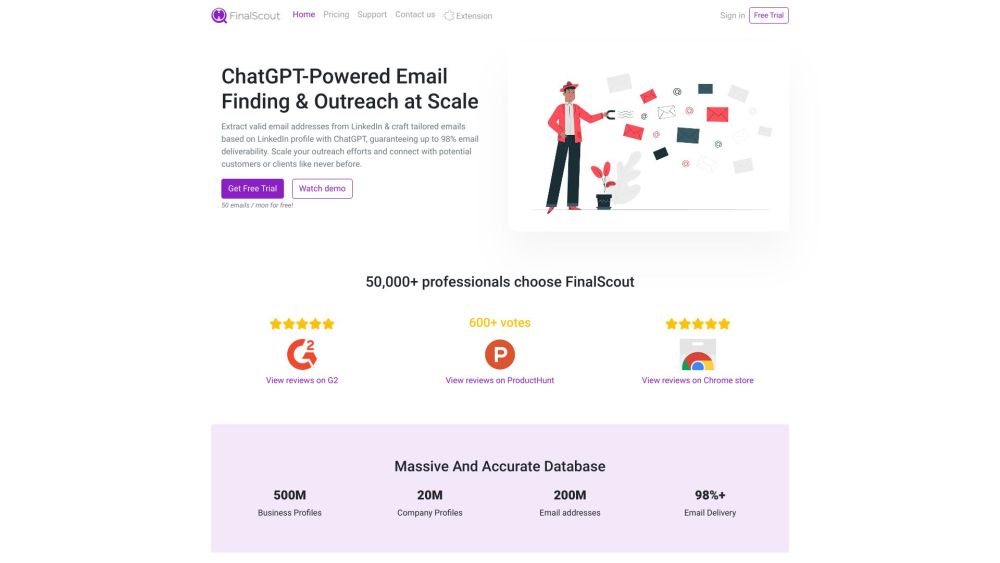
افتح قوة استخراج البريد الإلكتروني من لينكيد إن واغتنم استراتيجيات الوصول المخصصة باستخدام شات جي بي تي. ارتقِ بلعبة الشبكات الخاصة بك وتواصل بشكل فعال مع جمهورك المستهدف!
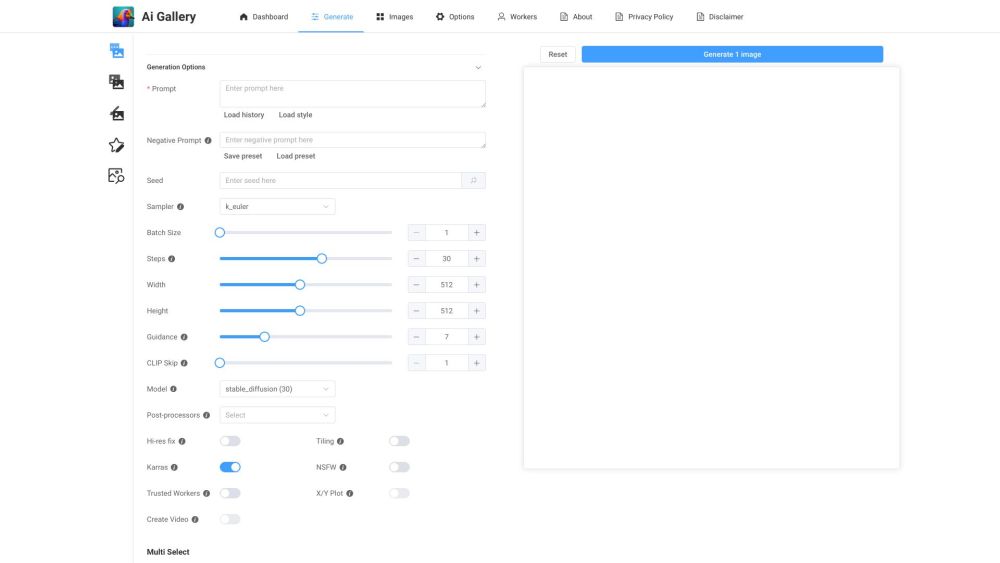
أطلق إبداعك مع مولِّد الفن بالذكاء الاصطناعي في AI Gallery، المصمم لمساعدتك في إنجاز أعمال فنية مذهلة في لمح البصر.
Find AI tools in YBX
Related Articles
Refresh Articles