Con Quiet-STaR, los Modelos de Lenguaje Aprenden a Analizar Antes de Responder.
Most people like

OpenL es una avanzada herramienta de traducción impulsada por IA, diseñada para facilitar la traducción de textos entre idiomas. Mejora tu comunicación con nuestra solución innovadora, que derriba barreras lingüísticas y conecta a las personas en todo el mundo.
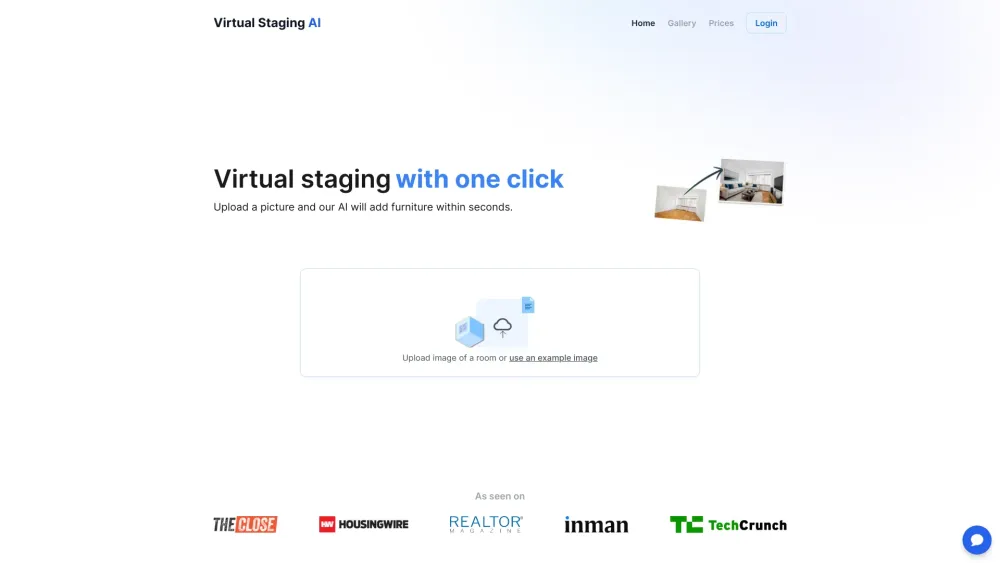
Transforma tus anuncios con nuestra aplicación de presentación virtual impulsada por IA para profesionales inmobiliarios
Descubre cómo nuestra innovadora aplicación de presentación virtual basada en IA puede elevar tus anuncios de bienes raíces. Diseñada específicamente para profesionales del sector, esta poderosa herramienta te permite crear visuales impresionantes y realistas que cautivan a los compradores potenciales y mejoran el atractivo de las propiedades. Mejora tu estrategia de marketing y destaca en un mercado competitivo con nuestra tecnología de vanguardia diseñada para agilizar el proceso de exhibición de propiedades.
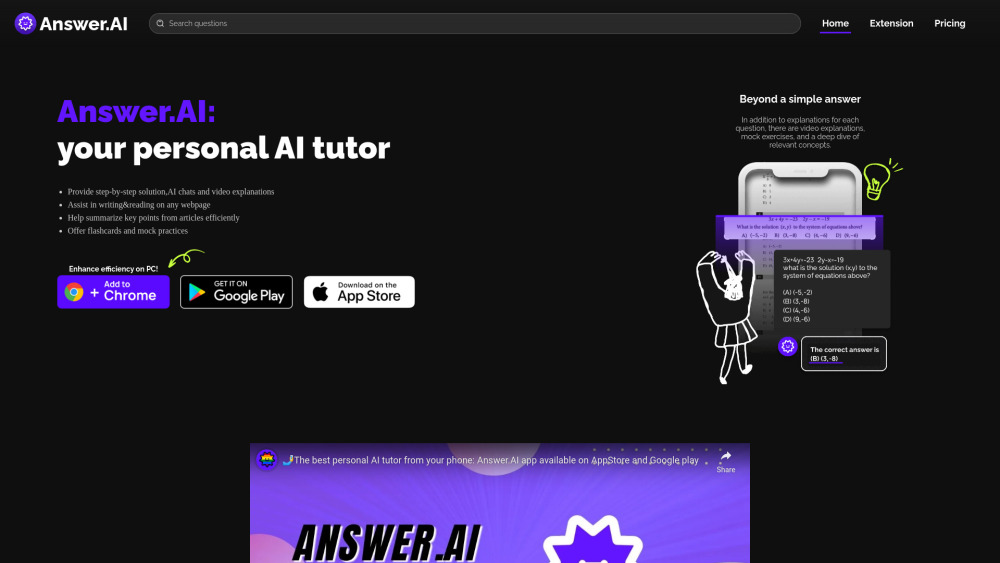
Desbloquea el potencial de tu trayectoria académica con nuestra innovadora app de ayuda para tareas impulsada por inteligencia artificial. Diseñada para ayudar a los estudiantes a dominar materias complejas, esta herramienta ofrece orientación personalizada y apoyo instantáneo ante cualquier desafío académico. Ya seas que enfrentes problemas matemáticos o explores la literatura, nuestra app simplifica el aprendizaje con recursos a medida al alcance de tu mano. ¡Experimenta el futuro de la educación y mejora tus sesiones de estudio hoy mismo!
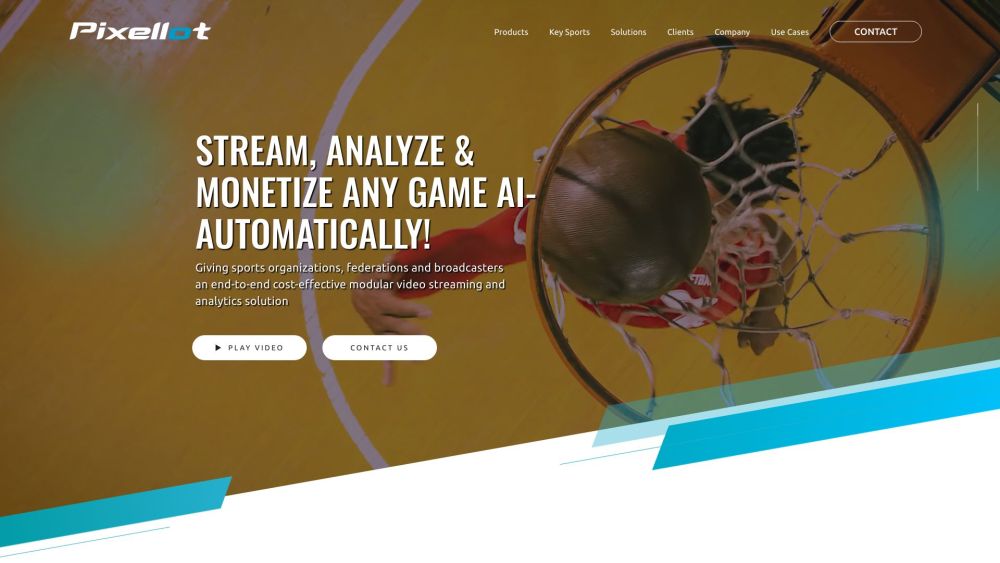
Descubre cómo las cámaras deportivas impulsadas por IA están transformando el panorama de la cobertura, transmisión y análisis deportivo. Estos sistemas innovadores mejoran la calidad de la transmisión en vivo y ofrecen un análisis exhaustivo del rendimiento, brindando a aficionados y entrenadores información sin precedentes sobre cada juego. Acompáñanos mientras exploramos el futuro de la tecnología deportiva y el impacto de la automatización en la captura de la emoción de los eventos atléticos.
Find AI tools in YBX
