Desatando GPT-4: Rendimiento Asombroso en Evaluaciones Oftálmicas y Recomendaciones Expertas para una Implementación Cautelosa
Most people like
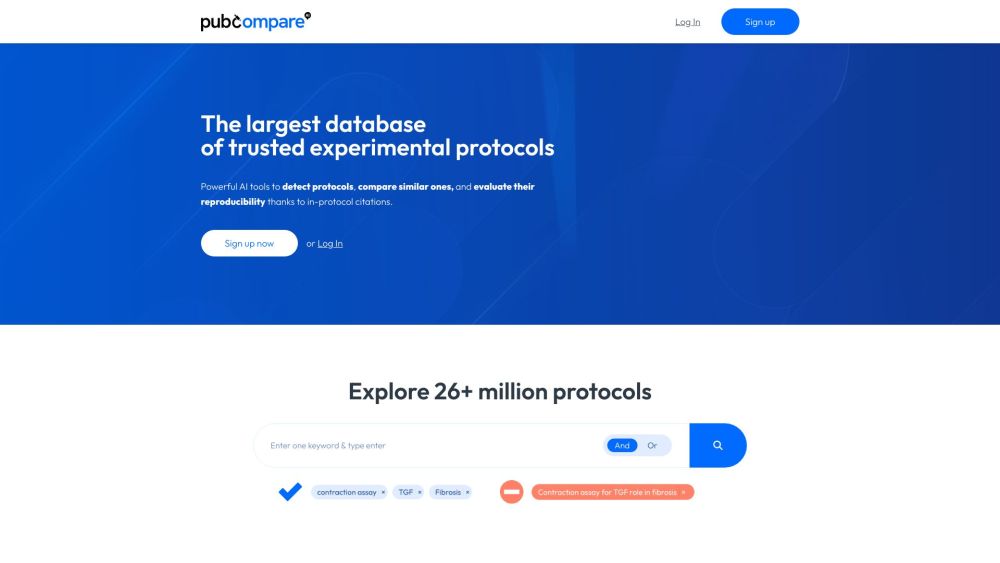
En la investigación y la experimentación científica, la reproducibilidad es fundamental para validar resultados y asegurar credibilidad. Al comparar sistemáticamente diferentes protocolos, los investigadores pueden identificar las mejores prácticas y procedimientos estándar que mejoran la reproducibilidad. Este proceso no solo ayuda a perfeccionar las metodologías, sino que también fomenta la colaboración y la confianza dentro de la comunidad científica. Descubre cómo la comparación de protocolos puede conducir a resultados más confiables y impulsar el progreso en tu campo.
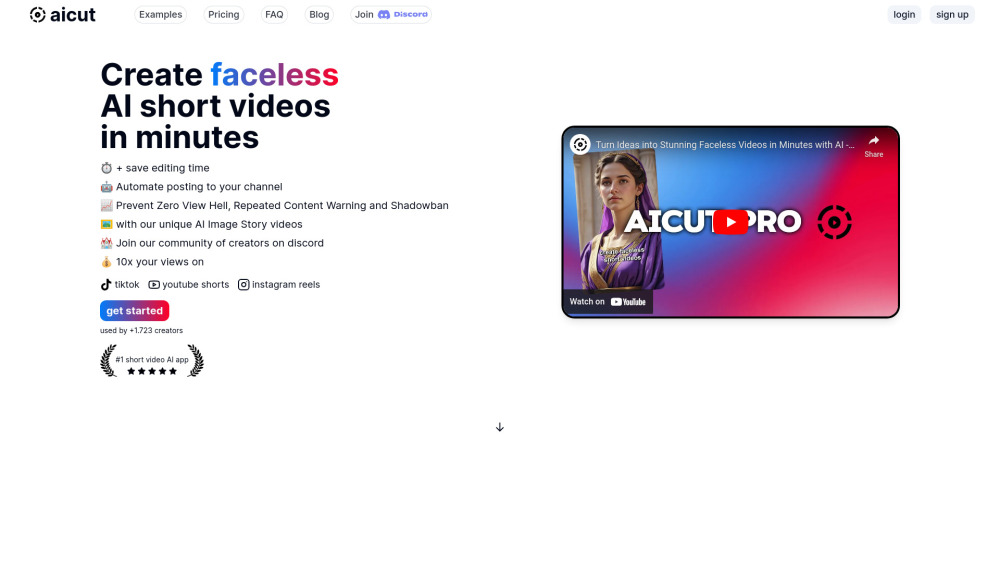
¿Estás listo para mejorar tu proceso de creación de contenido? Nuestra innovadora herramienta de IA permite a los usuarios producir fácilmente cautivadores videos cortos sin necesidad de aparecer en ellos. Ya seas un comercializador, educador o entusiasta de las redes sociales, esta plataforma fácil de usar simplifica la experiencia de creación de videos. ¡Sumérgete en un mundo de narración sin límites y potencia tu presencia en línea hoy mismo!

Sube fácilmente tus fotos y obtén marcos hermosos para comprarlos en línea hoy mismo.
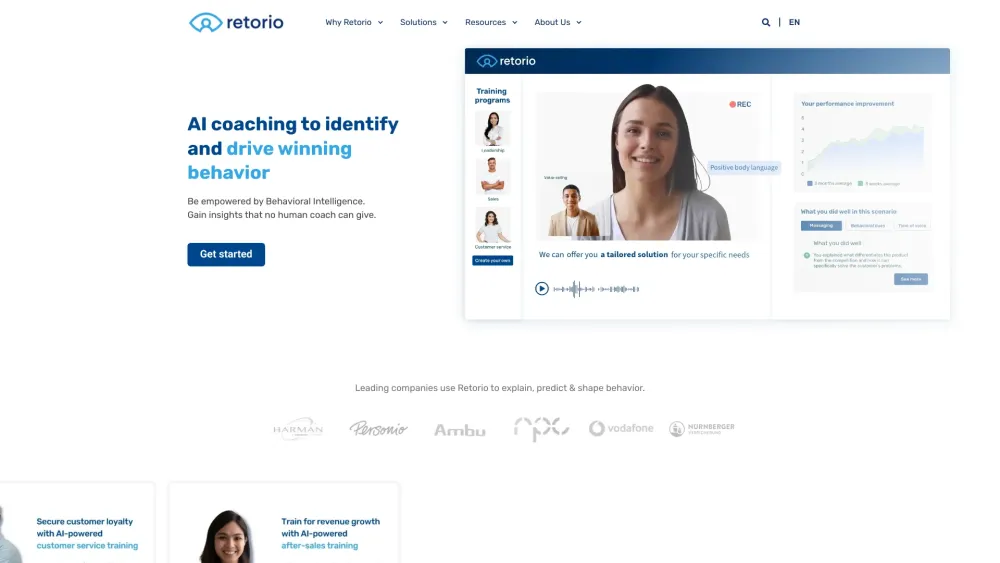
Desbloquear el potencial de una cultura centrada en el rendimiento depende de estrategias efectivas de Aprendizaje y Desarrollo (A&D) impulsadas por la Inteligencia Conductual. Al integrar conocimientos de la ciencia del comportamiento, las organizaciones pueden mejorar el compromiso de los empleados, optimizar los programas de capacitación y fomentar un entorno laboral más dinámico. Este enfoque no solo promueve el aprendizaje continuo, sino que también impulsa el éxito organizacional al alinear el crecimiento de los empleados con los objetivos empresariales. Descubre cómo cultivar una cultura de rendimiento próspera a través de prácticas innovadoras de A&D respaldadas por la Inteligencia Conductual.
Find AI tools in YBX
