Google lanza la serie Gemma 2: Presentamos un modelo de 27 mil millones de parámetros que puede funcionar con solo un TPU.
Most people like
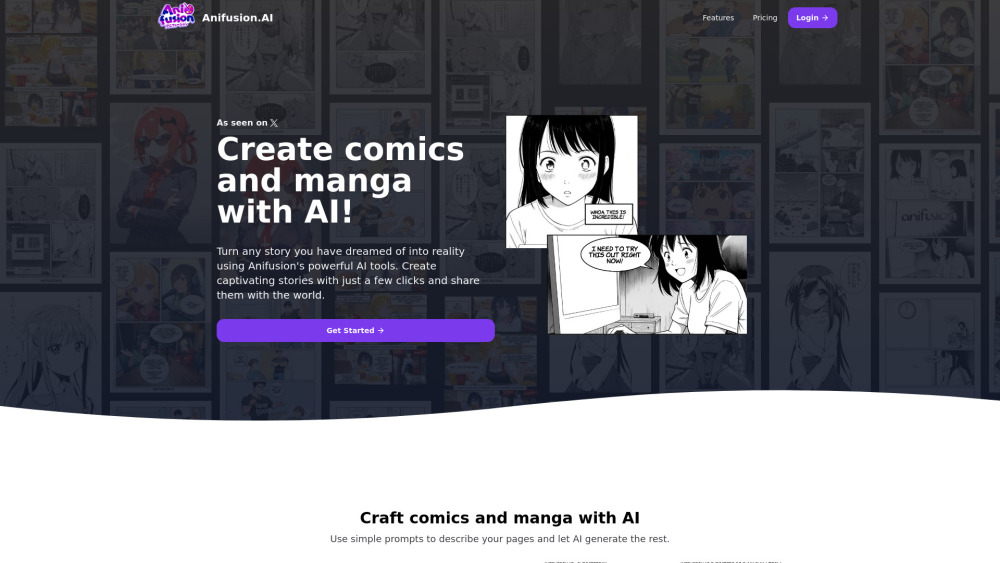
Descubre la herramienta de IA definitiva diseñada para crear cómics y manga impresionantes sin esfuerzo. Perfecta para artistas y narradores, esta innovadora plataforma simplifica el proceso de creación de cómics, permitiéndote dar vida a tus visiones creativas con facilidad. Libera tu imaginación y elabora visuales cautivadores que atrapen a los lectores, todo con el poder de la IA al alcance de tu mano.
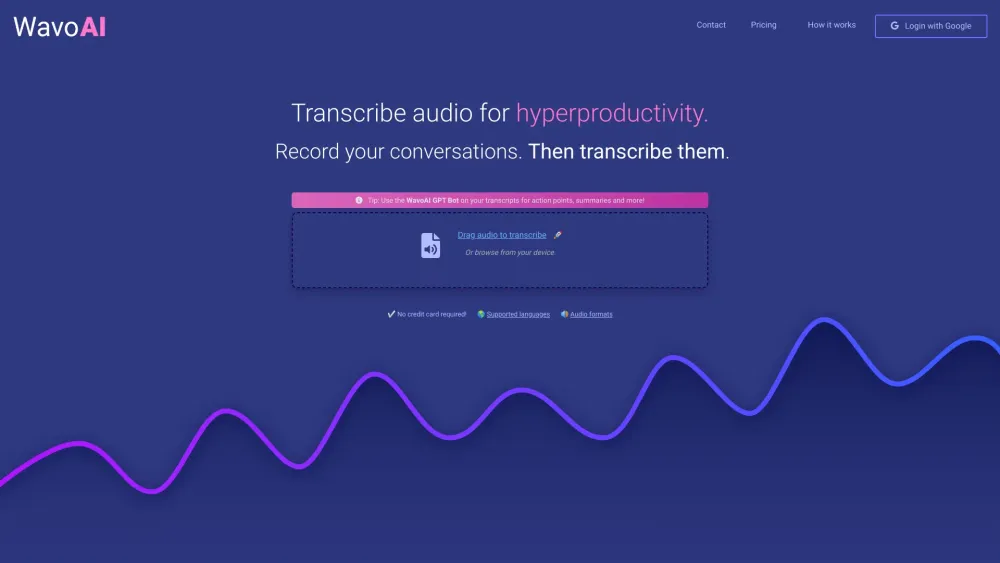
Desbloquea tu potencial y optimiza tu flujo de trabajo con la tecnología de transcripción de audio impulsada por IA. Al convertir palabras habladas en texto escrito, esta innovadora herramienta no solo te ahorra tiempo, sino que también mejora la eficiencia en la toma de notas, la documentación de reuniones y la creación de contenido. Descubre cómo la transcripción de audio con IA puede transformar tu productividad y revolucionar la forma en que gestionas la información.
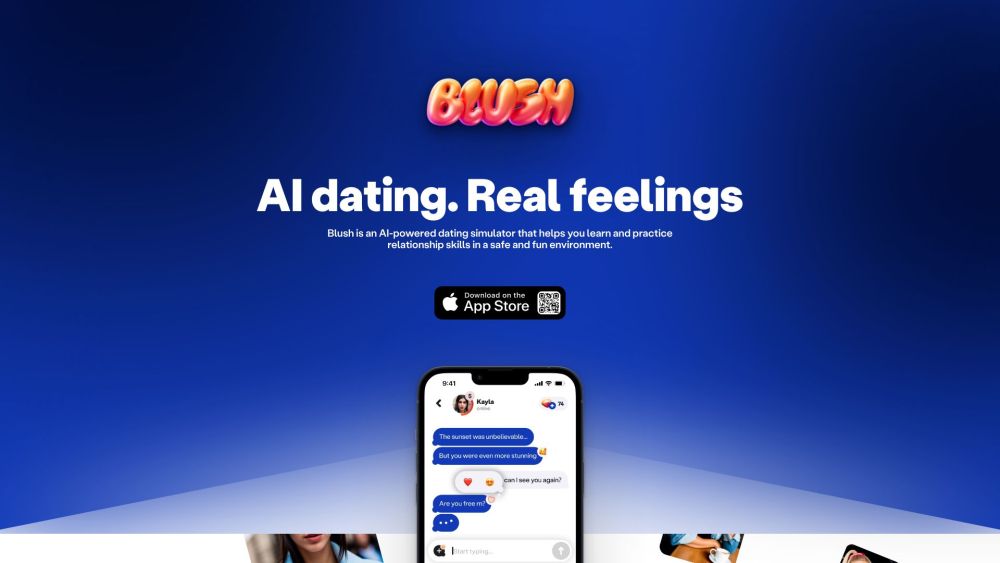
Blush es un innovador simulador de citas impulsado por inteligencia artificial, diseñado para mejorar las habilidades de relación de los usuarios y aumentar su confianza en situaciones románticas.
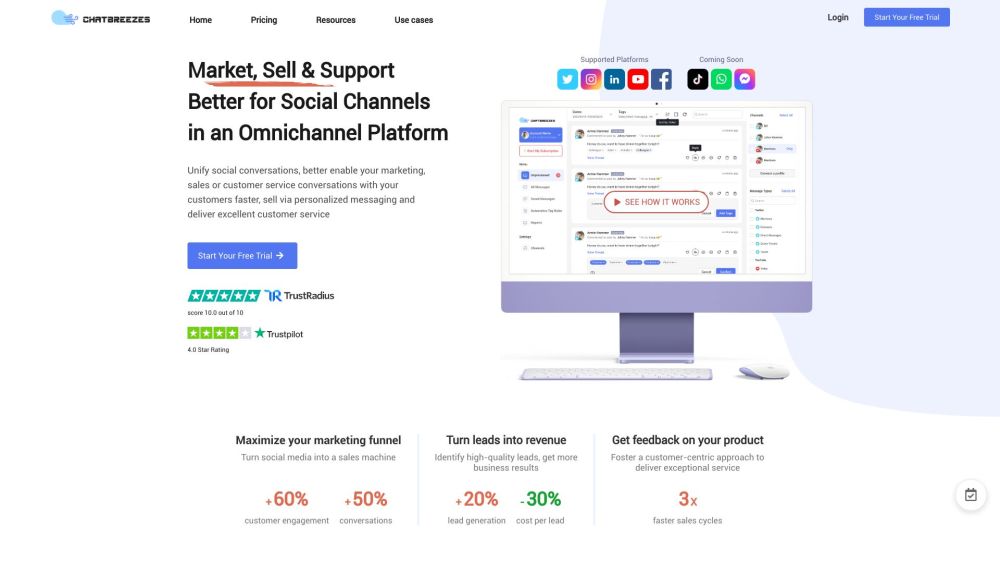
Find AI tools in YBX
Related Articles
Refresh Articles