LMSYS Presenta 'Multimodal Arena': GPT-4 Lidera el Ranking, Pero la Visión Humana Sigue Siendo Inigualable
Most people like

Transforma cualquier texto en cuestionarios atractivos con nuestro generador de cuestionarios impulsado por IA. Crea sin esfuerzo evaluaciones interactivas que mejoran el aprendizaje y la retención, haciendo que la educación sea más accesible y placentera. Perfecto para educadores, estudiantes o cualquier persona que desee poner a prueba sus conocimientos, nuestra herramienta simplifica el proceso de creación de cuestionarios y potencia la comprensión. ¡Sumérgete en el futuro del aprendizaje con nuestro innovador generador de cuestionarios!
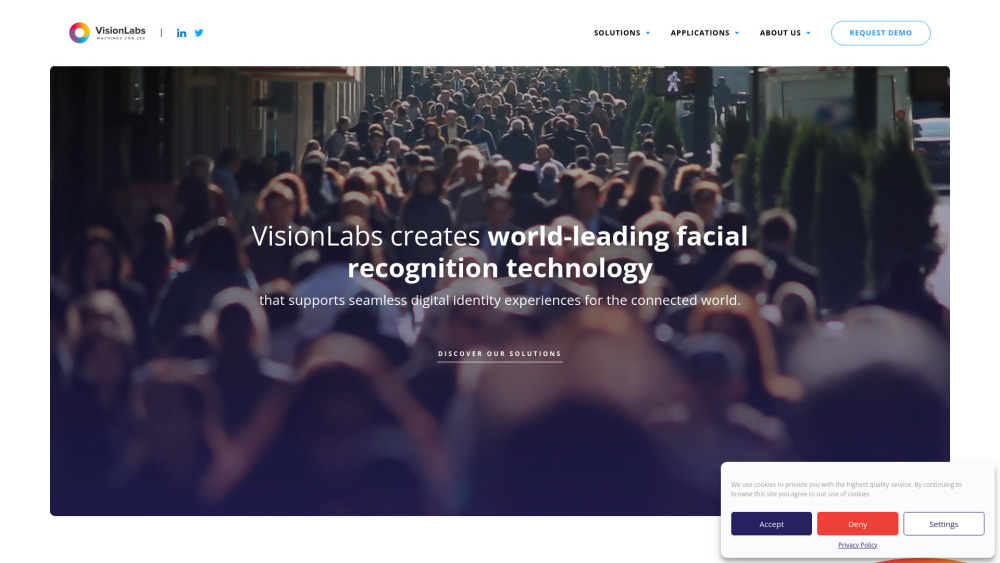
Desbloqueando Identidades Digitales Seguras con Tecnología de Reconocimiento Facial

Descubre una plataforma dinámica para la exploración fantástica y el chat de rol inmersivo. Conéctate con una comunidad vibrante mientras te embarcas en emocionantes aventuras, creas personajes intrincados y participas en emocionantes tramas. Ya seas un apasionado del rol o nuevo en el género, nuestra plataforma ofrece herramientas y recursos diseñados para mejorar tu experiencia en los reinos fantásticos de tu imaginación. ¡Únete a nosotros hoy y desata tu creatividad!
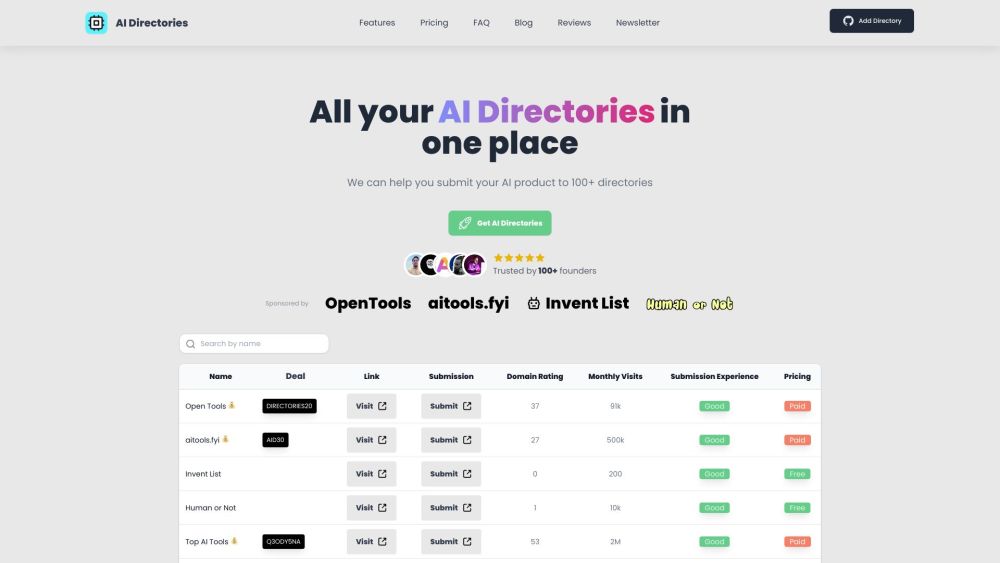
Descubre nuestra cuidada colección de herramientas de IA de vanguardia, diseñadas para elevar tus proyectos y optimizar tus flujos de trabajo. Desde la creación de contenido hasta el análisis de datos, estos recursos innovadores te permiten aprovechar al máximo el potencial de la inteligencia artificial. ¡Sumérgete y explora el futuro de la tecnología con nuestra completa selección de las mejores herramientas de IA!
Find AI tools in YBX
Related Articles
Refresh Articles