La investigación innovadora de IA de Apple ofrece alto rendimiento a un precio asequible.
Most people like
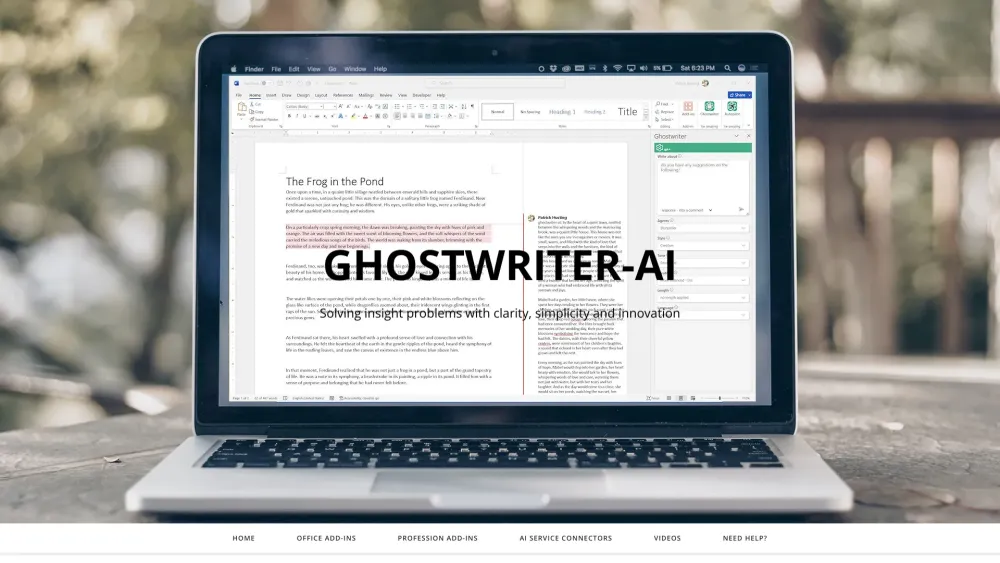
Transforma tu experiencia en Microsoft Office con soluciones de inteligencia artificial revolucionarias
Desbloquea todo el potencial de Microsoft Office con innovaciones de IA que mejoran la productividad y optimizan tu flujo de trabajo. Descubre cómo estas herramientas avanzadas pueden revolucionar tu forma de crear, colaborar y comunicarte en tus aplicaciones de Office favoritas. Ya sea que desees automatizar tareas tediosas o elevar la creación de documentos, nuestras soluciones de IA están aquí para redefinir tu experiencia en Microsoft Office.
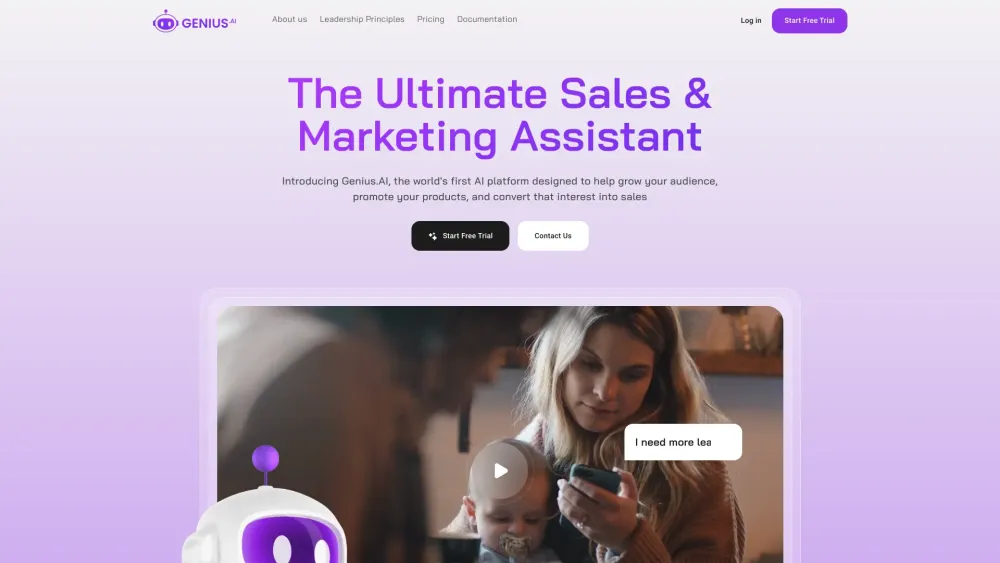
En el panorama digital actual, aprovechar la Inteligencia Artificial en Redes Sociales es esencial para impulsar estrategias de ventas y marketing exitosas. Esta tecnología innovadora permite a las empresas analizar el comportamiento del consumidor, optimizar la segmentación de campañas y agilizar los esfuerzos de engagement. Al integrar soluciones de IA, las marcas pueden desbloquear valiosos insights, crear experiencias personalizadas y, en última instancia, aumentar las tasas de conversión. Descubre cómo la IA en Redes Sociales puede transformar tus enfoques de ventas y marketing para mantenerte por delante de la competencia.
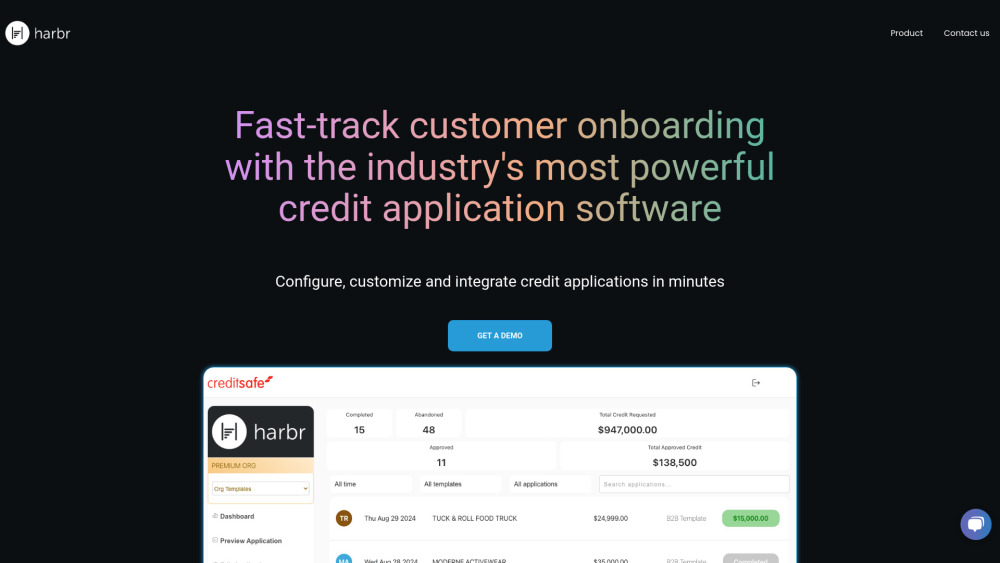
Desbloquea un proceso de incorporación fluido con software de solicitud de crédito impulsado por IA, diseñado para la eficiencia.
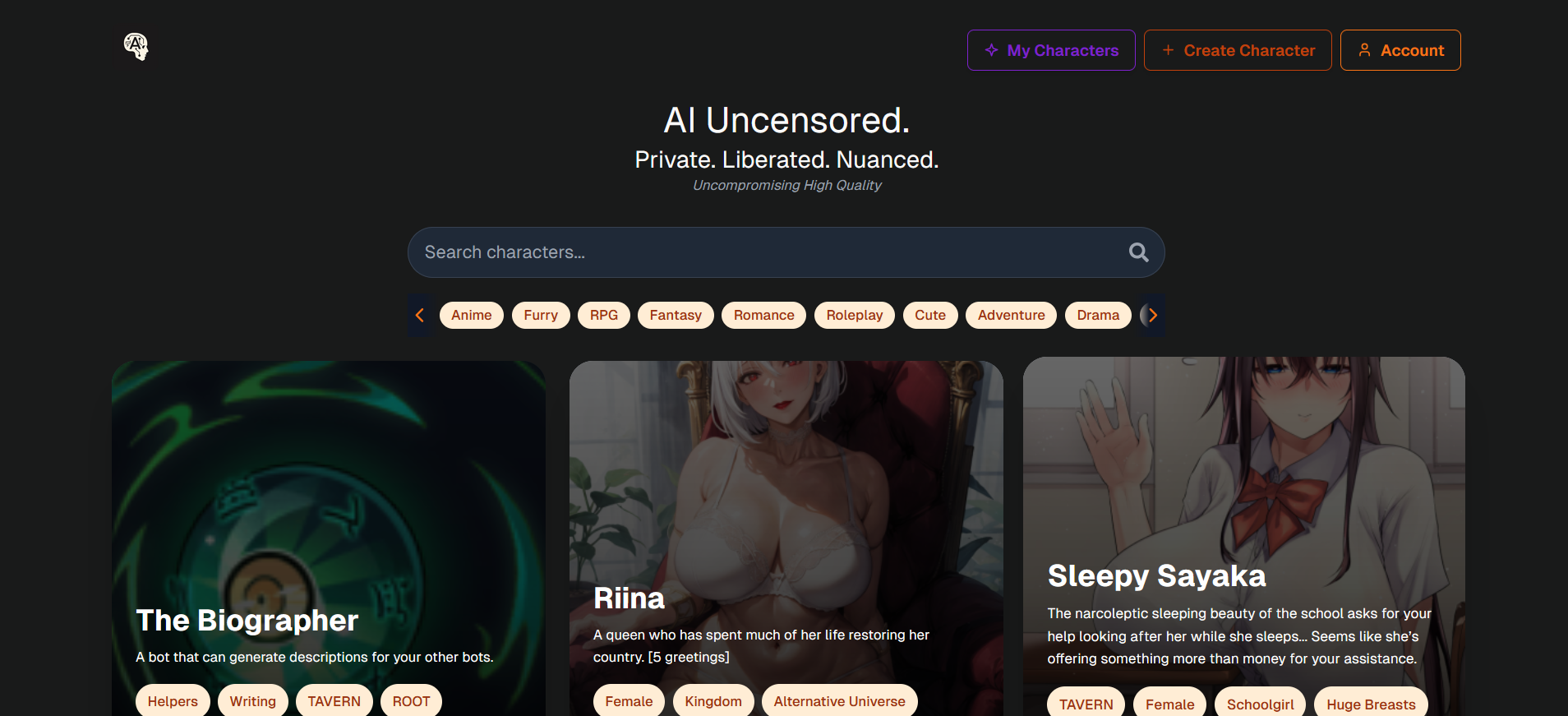
Mensajería AI ilimitada con miles de personajes AI sin censura. Para conversaciones creativas y privadas.
Find AI tools in YBX
Related Articles
Refresh Articles